AIO・SEO
AIO・SEOブログ
ChatGPTに引用されるには?LLMO対策の具体的手法11選【2026年最新】
2026.03.03 SEO
この記事の監修SEO会社
株式会社NEXER
2005年にSEO事業を開始し、計5,000社以上にSEOコンサルティング実績を持つSEOの専門会社。
自社でSEO研究チームを持ち、「クライアントのサイト分析」「コンテンツ対策」「外部対策」「内部対策」「クライアントサポート」全て自社のみで提供可能なフルオーダーSEOを提供している。
SEOのノウハウを活かして、年間数百万PVの自社メディアを複数運営。
「ググる」から「AIに聞く」へ、私たちの情報収集は今、歴史的な転換点を迎えています。
検索の主役が検索エンジンから、ChatGPTをはじめとする対話型AIへとシフトする中で、企業のデジタル戦略も根本的な見直しを迫られています。
AIが回答を生成する際、その情報源として自社のコンテンツが「引用される」ことで、ブランドの信頼性向上と、新たな流入経路の確保につながります。
ChatGPTに引用されるには、「AIにとっての理解しやすさ(構造化)」と「情報の信頼性(E-E-A-T)」を両立させることにあります。
本記事では、この最適化手法であるLLMO(大規模言語モデル最適化)について、引用の仕組みから文章表現レベルの具体的な11の対策まで、2026年の最新データを交えて解説します。
検索エンジンに依存しない、次世代の集客構造を築くための参考にしてください。

SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
目次
- 1 ChatGPTでの引用対策が注目される背景
- 2 【引用例公開】ChatGPTに引用されるとは?
- 3 ChatGPTの引用対策「LLMO」とは?
- 4 ChatGPTに引用されるメリット
- 5 ChatGPTがWebページを引用する仕組み
- 6 ChatGPTに引用されるためのLLMO対策11選
- 7 ChatGPTに引用されない時の考えられる原因
- 8 ChatGPTの引用からの流入を確認・測定できるツール
- 9 ChatGPTに関する2026年の最新ニュース
- 10 ChatGPTのLLMO対策に関するよくある質問(FAQ)
- 11 まとめ:ChatGPTへの引用は「信頼」の証。LLMO対策でブランド価値から流入へ
- 12 お問い合わせ
ChatGPTでの引用対策が注目される背景
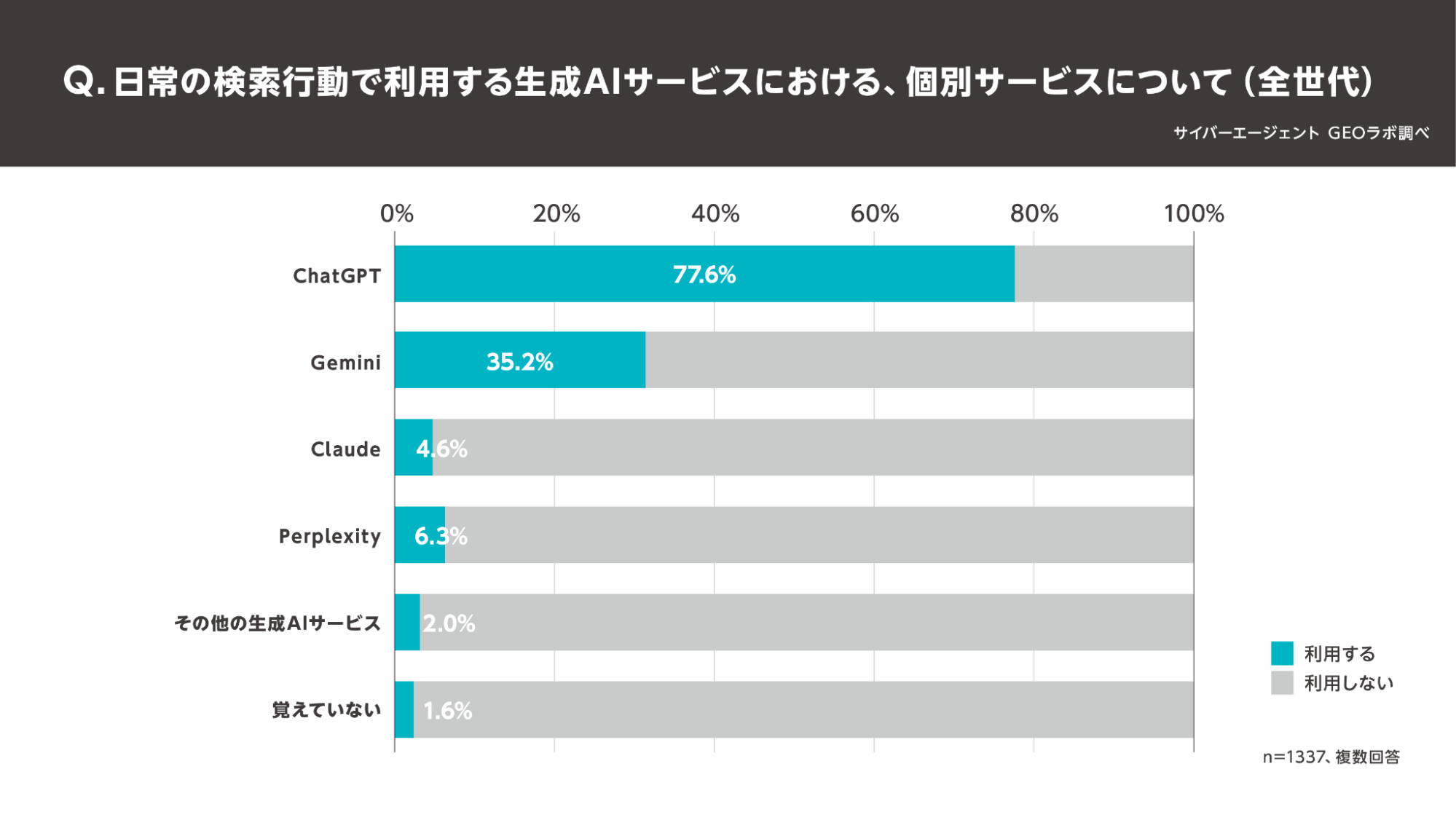
参照:サイバーエージェント GEOラボ「生成AIのユーザー利用実態調査を実施」
ChatGPTでの引用対策が注目されている最大の理由は、ユーザーの検索行動の主役が「検索エンジン」から「AI対話」へと決定的にシフトし始めているからです。
株式会社サイバーエージェントの調査によれば、日常の検索で生成AIを利用するユーザーの「77.6%」がChatGPTを選択しており、新たな検索プラットフォームとしての地位を確立しています。
(※2025年5月、全国10代~60代の男女9,278名を対象)
またこの別の調査では、10代においては、ChatGPTの利用率が「42.9%」に達し、国内大手の「Yahoo! JAPAN」の31.3%を上回る逆転現象さえ起きています。
このように「AIから直接回答を得る」ことが一般化した現代において、AIに自社情報を正しく引用・参照させるための対策は、従来のSEOを凌ぐ重要性を持つ最優先の生存戦略となっています。
【引用例公開】ChatGPTに引用されるとは?

「ChatGPTに引用される」とは、AIが回答を生成する際の「信頼できるエビデンス」として特定のサイトを選別し、情報を回答へ直接組み込む状態を指します。
上図に示した弊社のサイトの引用事例においても、AIは以下の3つの形式で弊社のコンテンツを引用・参照しています。
-
「回答テキスト内」
AIの回答を構成する「核」となる知識として、サイト内の情報が文章の中に自然な形で統合されます。 -
「文中の引用枠」
提示した情報の信憑性を裏付ける「根拠」として、該当箇所のすぐ横にサイトへの直接的なリンクが設置されます。 -
「末尾の情報源リスト」
回答の最後に「参考文献」としてURLが集約され、コンテンツの権威性と参照の利便性を視覚的に担保します。
このように、AIの回答の一部として引用されることは、単なる検索順位の獲得以上にユーザーからの厚い信頼を生み出し、引用からの流入や指名検索の増加につながります。
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
ChatGPTの引用対策「LLMO」とは?

LLMOとは「Large Language Model Optimization(大規模言語モデル最適化)」の略称であり、生成AIに自社情報を正しく理解・引用させるための手法です。
これまでの「検索エンジン」を対象とした施策から、「AIモデル」そのものに最適化を図る点が最大の特徴と言えます。
従来のSEOや、広義のAI検索対策であるAIOとは何が異なるのか。
まずはその定義の境界線を整理して解説します。
SEOとLLMOの違い
SEOとLLMOの決定的な違いは、「最適化の対象」と「目指すゴール」にあります。
SEOはGoogleなどの「検索エンジン」を対象に、検索結果画面で「上位表示」されることを目指す技術です。
これに対し、LLMOはChatGPTなどの「大規模言語モデル(LLM)」を対象とし、AIが回答を生成する際の「引用元」として選ばれることを目的としています。
| SEO | LLMO | |
|---|---|---|
| 最適化の対象 | Googleなどの「検索エンジン」 | ChatGPTなどの「AIモデル」 |
| 主な目的 | 検索結果での「上位表示」 | AI回答内での「引用・参照」 |
| ユーザー行動 | リンク一覧からサイトを選択 | 回答を読み、出典元を確認 |
| 評価の指標 | 検索順位・クリック率(CTR) | 引用率・ブランドの認知向上 |
AIOとLLMOの違い
AIOとLLMOの定義は、AI技術の急速な進化に伴い業界内で「自然発生的に生まれたもの」であり、現時点で公的に確立された定義は存在しません。
一般的には、AIO(AI Search Optimization)をAI検索対策全般を包含する「広義の概念」と捉え、その中にChatGPTなどの対話型AIに特化したLLMOが含まれるというイメージで語られることが多くなっています。
一方で、マーケティング現場の一部では、AIOをGoogleの「AI Overviews」限定の対策と定義するケースも見受けられ、文脈による使い分けが必要です。
名称や定義の範囲に違いはあっても、AIに信頼できる情報源として「引用されること」を最終的な目的としている点は共通しています。
| AIO | LLMO | |
|---|---|---|
| 概念の広さ | AI検索対策全般を指す「広義」の用語 | 大規模言語モデルに特化した「狭義」の施策 |
| ターゲット | AI検索プラットフォーム全般 | ChatGPT, Claude, Geminiなどの大規模言語モデル |
| 解釈の揺れ |
一部では… AI Overviews限定の対策と捉えるケースもある |
一部では… 引用されることより、学習させやすくさせることと定義されるケースがある |
ChatGPTに引用されるメリット
ChatGPTに引用されることは、従来の検索エンジン経由の流入とは異なる「新たな集客の柱」を構築することに繋がります。
特にユーザーが検索結果画面で行動を完結させるゼロクリック検索が強まる中、AIの回答という「信頼の枠」に自社情報が組み込まれる意味は大きいと言えるでしょう。
ブランド認知の拡大から流入経路の多角化まで、LLMOがもたらすメリットを解説します。
- SEOに依存しない新しい流入経路を得られる
- シェアの高いAIモデルのため露出が増える
- 認知されることで指名検索が増える
- 他のAIモデルからも引用されやすくなる
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
SEOに依存しない新しい流入経路を得られる
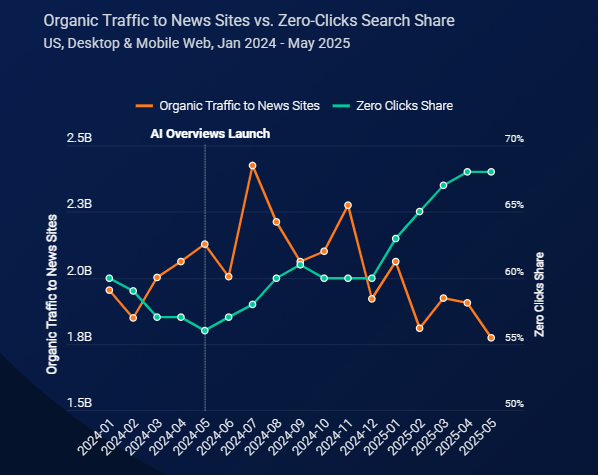
参照:similarweb「As zero-click searches rise, news sites lose organic traffic」
ChatGPTに引用されることは、検索エンジンのアルゴリズムに左右されない「第三の流入チャネル」を構築することを意味します。
上のグラフは、similarwebの調査によるGoogleがAI Overviewsを導入して以降の、ニュースサイトへの流入とゼロクリック検索の関係を調査したデータです。
導入後の1年間で、サイトへ遷移せずに検索結果で行動が完結する「ゼロクリック検索」の割合は、56%から約68%へと上昇し、反対にサイトへの流入数は24億から17億にまで大幅に減少しました。
従来のSEOによる「露出」が必ずしも「流入」に結びつかなくなっている現状において、AIの回答内に「出典」として導線を確保できるLLMO対策は、検索プラットフォームに依存しない安定した集客経路となります。
シェアの高いAIモデルのため露出が増える
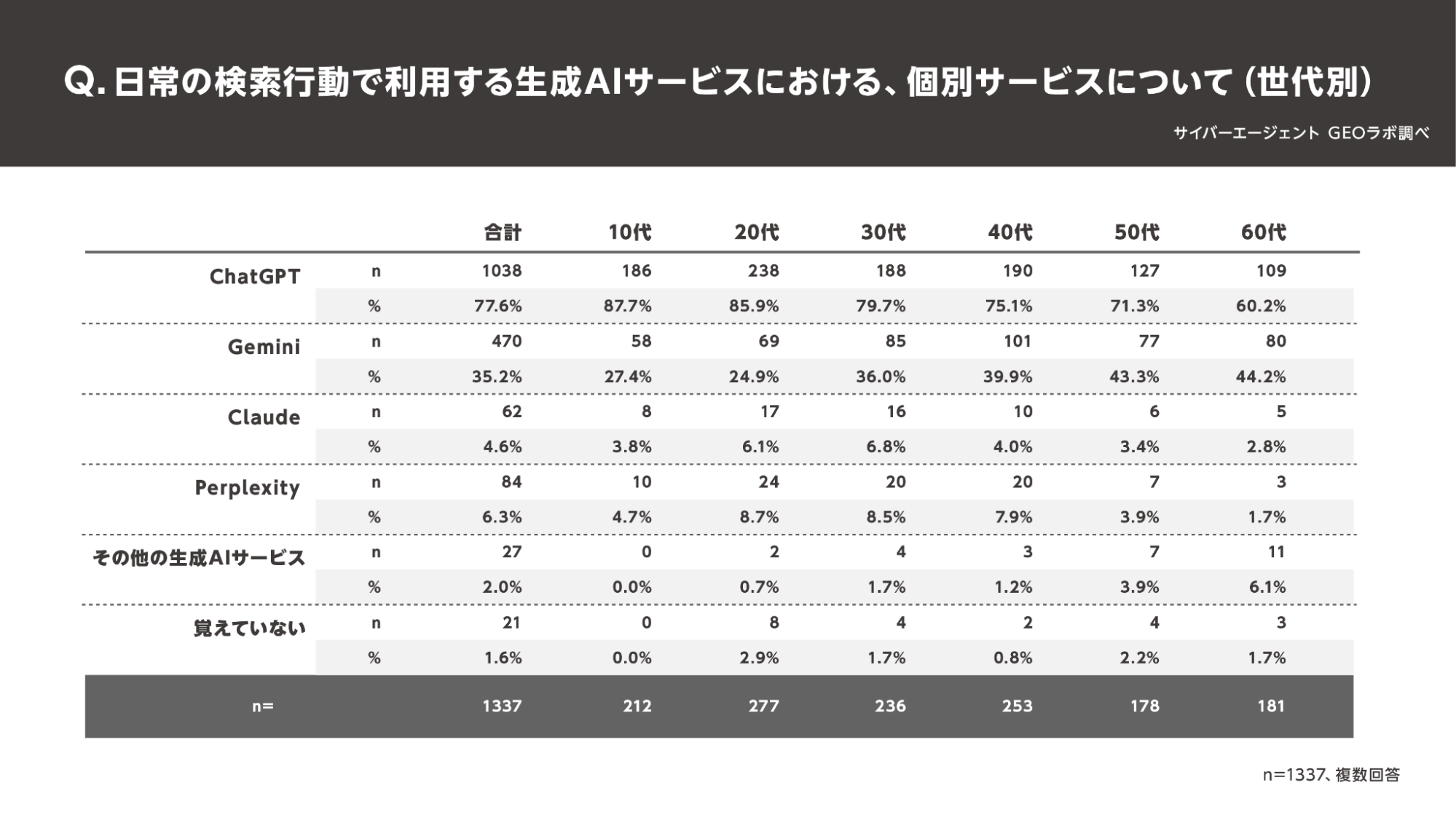
参照:サイバーエージェント GEOラボ「生成AIのユーザー利用実態調査を実施」
ChatGPTに引用されることは、圧倒的な市場シェアを持つプラットフォーム上で自社の情報を露出させることを意味します。
サイバーエージェントのGEOラボによる調査では、日常の検索行動で生成AIを利用するユーザーの「77.6%」がChatGPTを選択しており、2位のGemini(35.2%)を大きく引き離す独走状態にあります。(※2025年5月、全国10代~60代の男女9,278名を対象)
これほど高いシェアを誇るモデルにおいて「信頼できる情報源」として参照されることは、特定の検索キーワードで1位を獲得する以上に、膨大なユーザーの目に触れる機会を創出します。
特に若年層を含め、AIを主要な情報収集手段とする層が拡大している現状において、トップシェアのAI回答内に組み込まれることは、将来的な顧客接点を最大化するブランド露出戦略となるのです。
認知されることで指名検索が増える
ChatGPTに引用されることは、単なる一時的な流入に留まらず、中長期的な「ブランド資産」の構築に大きく貢献します。
これは、AIが専門的な回答の根拠として自社名を繰り返し提示することで、ユーザーの深層心理に「その分野の専門家」としての認知が刻まれるからです。
具体的には、以下のフローで「指名検索」へと繋がります。
- AIが回答を生成する際、その知識の「参照元」として自社名やサイト名が明示される。
- ユーザーは、AIが膨大なデータから選別した「信頼性の高いソース」として、そのブランドを「権威」として認識する。
- ユーザーがより詳細な情報や具体的なサービスを求めて、検索エンジンで「会社名」や「サイト名」を直接入力して検索を行う。
この流れで発生する指名検索は、競合他社との比較を介さないため、CV(成約)に至る確率が高いのが特徴です。
AIに「選ばれる」というプロセスそのものが、ユーザーからの「厚い信頼」を獲得するための強力な手段となります。
他のAIモデルからも引用されやすくなる
LLMO対策は特定のAIモデルに限定されたものではなく、「AIの参照ロジックそのもの」に最適化を図る手法です。
そのため、ChatGPTでの引用獲得は、「Gemini」や「Claude」、「Perplexity」といった他の主要なAIモデルにおける露出向上にも波及効果をもたらします。
これは、多くのAIがRAG(検索拡張生成)という共通の技術基盤を用いて情報を取得しているためです。
「構造化データの整備」や「情報の信頼性の向上」といったLLMOの施策は、AIの種類を問わず情報を理解しやすくするための普遍的な最適化と言えます。
ChatGPTがWebページを引用する仕組み

ChatGPTが回答を行う際、その裏側では高度な情報収集システムが作動しています。
単なる過去の学習データの出力だけではなく、外部検索エンジンとのリアルタイム連携や、AI専用クローラーによる情報の巡回を経て、最適なソースが選別されているのです。
さらに、収集した情報をAIが理解し信頼できる回答として統合する「RAG」という仕組みが大きな鍵を握っています。
ここでは、ChatGPTがWebページを特定し、引用に至るまでの技術的なプロセスを解説します。
- 検索プロバイダー(Bing等)との連携
- 参照・引用のためのクローラー「OAI-SearchBot」
- 検索拡張生成(RAG)による回答生成
検索プロバイダー(Bing等)との連携
ChatGPTは、リアルタイムな情報を取得するために外部の「検索プロバイダー」と強力に連携しています。
OpenAIの公式説明によれば、回答の生成プロセスについて次のように述べられています。
ご質問に関連する回答を提供するため、ChatGPT 検索は場合によって他の検索プロバイダーと提携します。その際、ChatGPT 検索は通常、あなたのクエリを1つ以上の目的に合わせたクエリに書き換え、それらを当該プロバイダーへ送信します。
この公式文には参照する検索プロバイダーとして「Bing」「Shopify」を例に挙げていることから、これらが中心的な役割を担っていると考えられます。
(※この2つと断定しているわけではない。)
ChatGPTは、ユーザーの質問をAIが処理しやすい形に最適化し、これらプロバイダーから得られた最新の検索インデックスを「回答のソース」として活用します。
つまり、LLMO対策においては、提携先のデータベース上で自社の情報が「信頼性の高い最新ソース」として評価されていることが、引用獲得のための重要な前提条件となります。
参照・引用のためのクローラー「OAI-SearchBot」
ChatGPTがWebサイトを巡回し、情報を最新のインデックスとして保持するために使用するのが、AI検索専用のクローラー「OAI-SearchBot」です。
OpenAIは、サイト運営者が自社コンテンツをChatGPTの回答に反映させるための条件として、以下のように明示しています。
サイトのコンテンツを ChatGPT の要約やスニペットに含めるには、OAI-SearchBot をブロックしていないことを確認してください。必要に応じて robots.txt を更新し、OAI-SearchBot がアクセスできるようにする必要があります。
つまり、Googleでの上位表示を目指すためにクローラーの巡回を許可するのと同様に、AI検索からの引用を狙うのであれば、この「OAI-SearchBot」に対して正しく情報を開示する必要があります。
もし「robots.txt」で、このボットを拒否する設定になっている場合、AIはサイトの最新情報を取得できず、引用の候補から外れてしまいます。
LLMO対策では、このAI専用クローラーにスムーズに情報を収集できる環境を整えることが重要です。
検索拡張生成(RAG)による回答生成
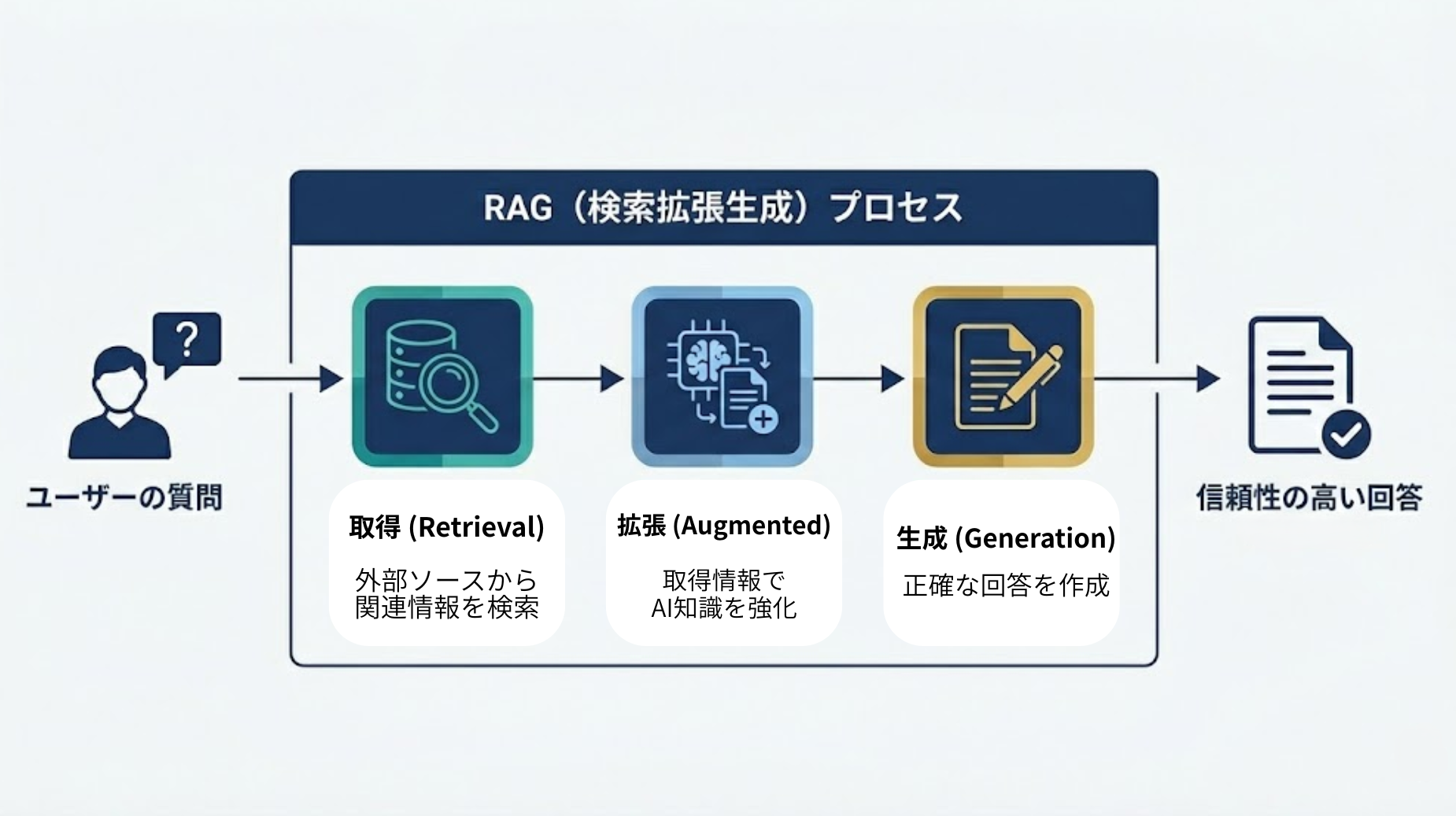
ChatGPTが最新情報を引用する根幹にあるのが「RAG(検索拡張生成)」という技術です。
これは、AIが持つ知識に外部の最新情報を組み合わせて回答を生成する仕組みで、以下の3つの要素で構成されています。
-
Retrieval(取得)
質問に関連する情報をWebなどの外部ソースから「検索して取ってくる」工程です。 -
Augmented(拡張)
取得した情報を追加のコンテキスト(背景知識)として利用し、AIが持つ元の知識を「補強・拡張」します。 -
Generation(生成)
拡張された情報に基づき、正確で一貫性のある回答を「作成」します。
このRAGにより、AI特有の「ハルシネーション(もっともらしい嘘)」を抑え、情報のソースを提示することで透明性と信頼性を高めることが可能になります。
単に学習データを出力するのではなく、最新の資料を参照しながら回答を練り上げる「調べ学習」のようなプロセスが、現在のAI検索の正体です。
ChatGPTに引用されるためのLLMO対策11選
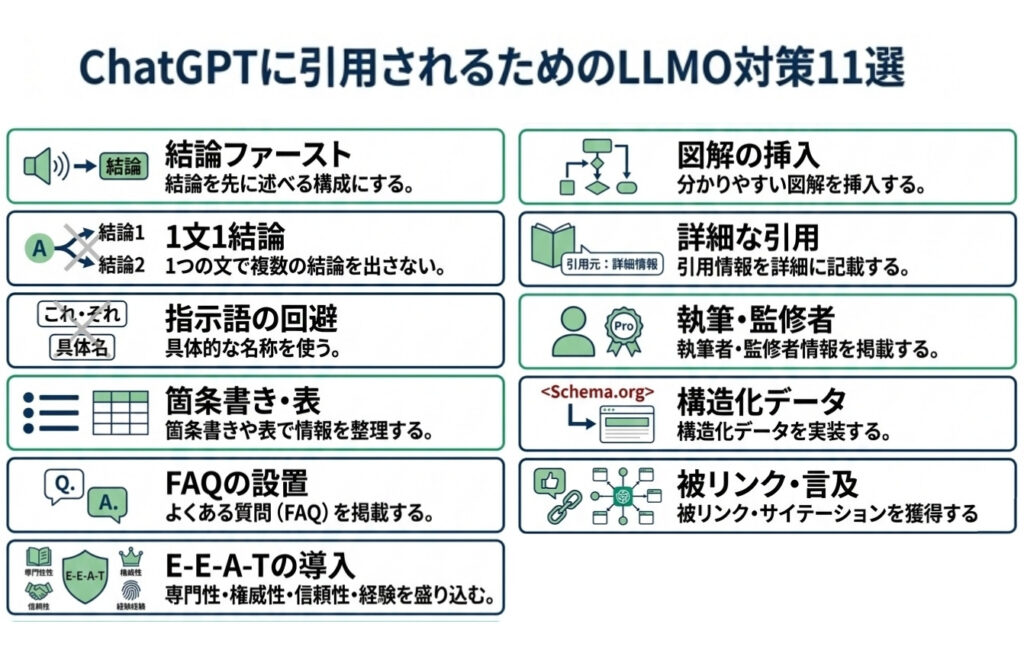
ChatGPTに、自社のコンテンツが優先的に選ばれるためには、AIにとっての「理解しやすさ」と「情報の信頼性」を高める必要があります。
従来のSEO対策をベースにしつつも、AIの参照ロジックに特化した最適化を行うことが、引用率向上のポイントとなります。
ここでは、LLMO対策として取り組むべき11個の具体的な施策を紹介します。
実践的な書き方をイメージしやすいよう「Before・Afterの比較例文」や、弊社事例を豊富に交えて解説します。
- 結論ファーストの文章にする
- 1文に2つ以上の結論を出さない
- 指示語(これ・それ)を避ける
- 箇条書きや表で情報を整理する
- FAQを設置する
- 情報にE-E-A-Tを取り込む
- 分かりやすい図解を挿入する
- 引用情報を詳細に記載する
- 執筆者・監修者情報を掲載する
- 構造化データを実装する
- 被リンク・サイテーションを獲得する
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
①結論ファーストの文章にする
AIからの引用率を高めるには、一文目(冒頭)にユーザーの問いに対する「直接的な回答」を配置することが有効です。
AIは情報の関連度を瞬時にスキャンしているため、文章の入り口に答えがあることで、その箇所を「最も重要な情報」と即座に判定できます。
逆に、情緒的な前置きや背景説明から始めてしまうと、AIが情報の核心を見つけるためのコストが上がり、結果として引用対象から外れてしまうリスクが高まります。
【Before】結論が後ろにある例文
現代のビジネスシーンでは、メール以外にも様々な連絡手段が登場し、業務の効率化が求められています。チーム全体の生産性を高め、情報共有の漏れを防ぐためには、ビジネスチャットの導入が最も有効です。場所を選ばずにリアルタイムでやり取りができるため、迅速な意思決定が可能になります。
【After】結論ファーストの例文
チームの生産性を高めるには、ビジネスチャットの導入が最も有効です。リアルタイムで迅速なやり取りができるため、情報共有の漏れを防ぎ、意思決定のスピードを大幅に向上させることができます。場所を問わずスムーズに連携できる点が、現代の働き方に最適です。
②1文に2つ以上の結論を出さない
AIからの引用率を最大化するには、「1文につき1つの結論」という構成を徹底します。
AIは文章を「意味の塊」として解析し、各要素の重要度を判定しています。
そのため1つの文に複数の主張が混在すると、AIは「どの情報が最も核心的なのか」を正確に判断できず、情報の抽出精度が低下します。
以下のように結論を分割して明示することで、AIはそれぞれの事実を「独立したエビデンス」として認識し、回答内へ正確に組み込めるようになります。
【Before】1文に結論が複数存在する例文
弊社のサービスは安価で導入しやすいですが、セキュリティも強化されており、金融機関での実績も豊富で信頼されています。
【After】1文につき1つの結論にした例文
弊社のサービスは安価で導入しやすいのが特徴です。
また、独自の技術によりセキュリティも強化されています。
その結果、金融機関での豊富な実績があり、高い信頼を得ています。
③指示語(これ・それ)を避ける
AIに情報を正しく認識させるためには、「これ」「それ」といった指示語の使用を避け、具体的な名詞に置き換えることが重要です。
AIは文脈を推測する能力を持っていますが、指示語の指す対象が曖昧な場合、情報の紐付けに失敗するリスクがあります。
指示語を具体的な「名詞」や「キーワード」へ書き換えることで、AIは文脈を過度に遡ることなく、その一文のみで内容を正確に理解できるようになります。
この「情報の独立性」を高める文章表現が、AIにとって引用しやすい良質なデータソースとなる基盤になります。
ただし、あまりに徹底しすぎると、キーワードの多用によるSEOペナルティを受けるリスクや、読者に違和感を与える場合があるので、ほどほどに留めるのがポイントです。
【Before】指示語の多用した例文
LLMOはAI検索への最適化施策です。
これを行うことでサイトの評価が高まり、引用の判断基準となります。
それによって、認知度を向上させることも可能になります。
【After】指示語を回避した例文
LLMOはAI検索への最適化施策です。
LLMO対策を行うことで、サイトの評価が高まり、引用の判断基準となります。
引用されることで、認知度を向上させることも可能になります。
④箇条書きや表で情報を整理する
AIが情報を効率的に抽出できるように、「箇条書き」や「表」を活用して視覚的・構造的に情報を整理します。
AIは回答を生成する過程で、Webページ上の情報を「構造」として把握しようとします。
特に、複数の条件や特徴を列挙する場合、テキストのみの記述よりも構造化された記述の方が、AIの回答内へそのまま引用される可能性が高まります。
【Before】箇条書きを使わない例文
SEO対策において重要な要素は3つあります。
1つ目はキーワード選定で、ユーザーの意図を汲み取ることが大切です。2つ目は高品質なコンテンツの作成で、読者の悩みを解決する必要があります。3つ目は被リンクの獲得で、外部サイトからの信頼を得ることが不可欠です。
【After】箇条書きを用いた例文
SEO対策の3つの重要要素
- キーワード選定…ユーザーの検索意図を正確に把握する
- コンテンツ制作…読者の課題を解決する質の高い情報を発信する
- 被リンク獲得…外部の信頼できるサイトからの評価を積み上げる
⑤FAQを設置する

自社サイト内への「FAQの設置」は、LLMO対策において引用率を引き上げる手法の一つです。
ChatGPTなどの対話型AIは「ユーザーの問いに対して直接回答する」という特性を持つため、あらかじめ「質問と回答」をセットで構造化しておくことで、AIが情報を抽出する際の精度が高まります。
上の弊社の事例のように、ユーザーが検索やプロンプトで入力するであろう「疑問文」をそのままQ(質問)に設定し、それに対する「簡潔な結論」をA(回答)の冒頭に配置するのが鉄則です。
ユーザーへの情報の網羅性と、AIへのアクセシビリティを両立させる上でも不可欠な施策と言えます。
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
⑥情報にE-E-A-Tを取り込む
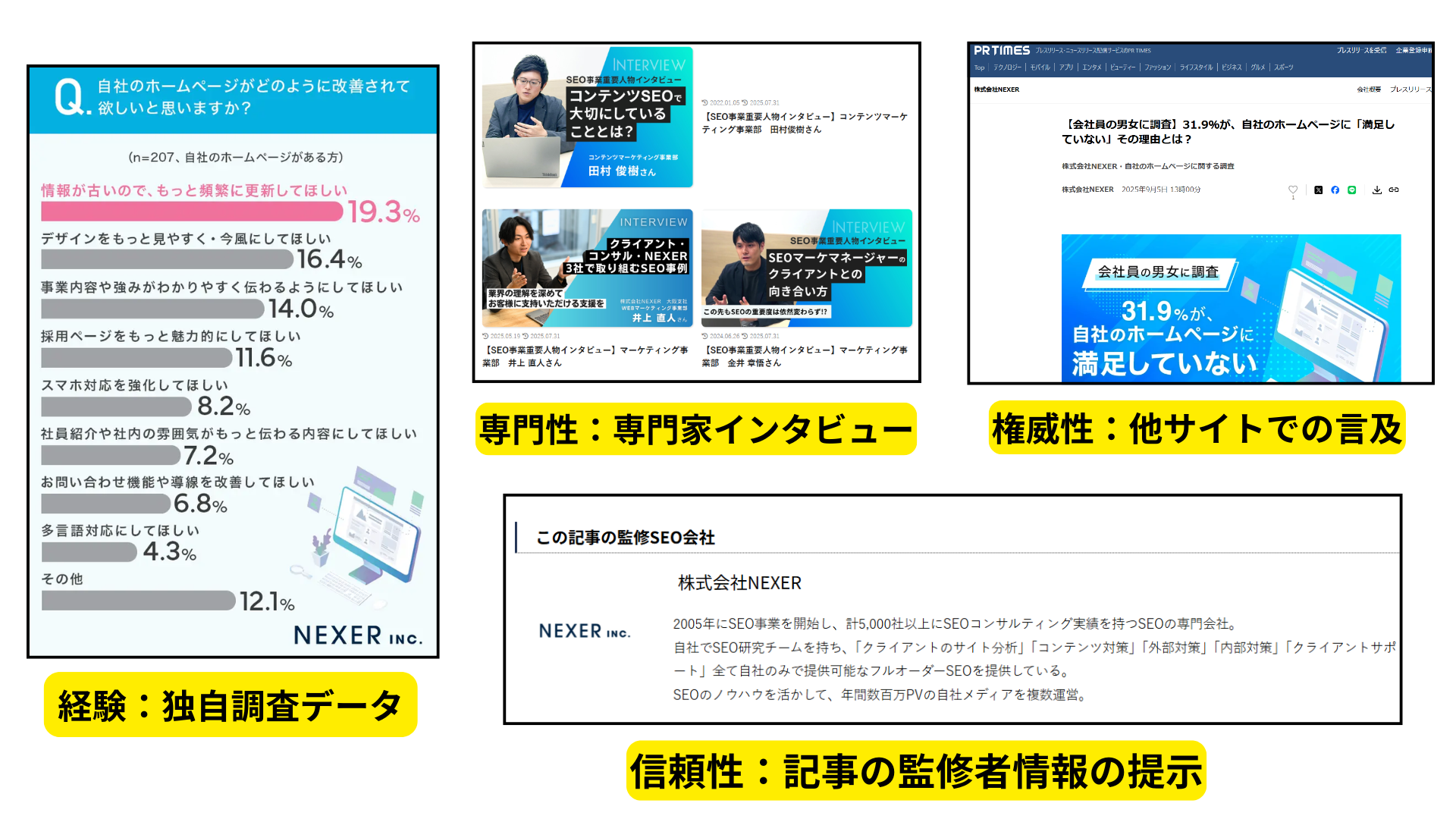
AIに信頼できる情報源として選ばれるためには、Googleが提唱する評価基準「E-E-A-T」をコンテンツに反映させることが重要です。
AIは回答を生成する際、ハルシネーション(もっともらしい嘘)を防ぐために「信頼性の高い根拠」を求めています。
そのため、誰でも書ける一般論ではなく、発信者の実体験や専門的な知見に基づいた情報は、引用の優先順位が劇的に高まります。
【E-E-A-Tの具体例】
-
Experience(経験)
製品を実際に使い込んで判明した独自のメリットや、自社で行った検証データの公開。 -
Expertise(専門性)
特定分野の有資格者による専門的な考察や、最新の技術動向を踏まえた深いレベルでの解説。 -
Authoritativeness(権威性)
業界内での受賞歴や、外部メディアからの言及、公的機関の統計を用いた裏付け。 -
Trustworthiness(信頼性)
責任ある運営者情報の明示や、根拠となる一次情報の提示、コンテンツの定期的な更新。
弊社においても、「独自のアンケート調査」「専門家へのインタビュー」「プレスリリースによる第三者の言及」「監修者情報の提示」といったE-E-A-Tを高める情報設計を行っています。
⑦分かりやすい図解を挿入する
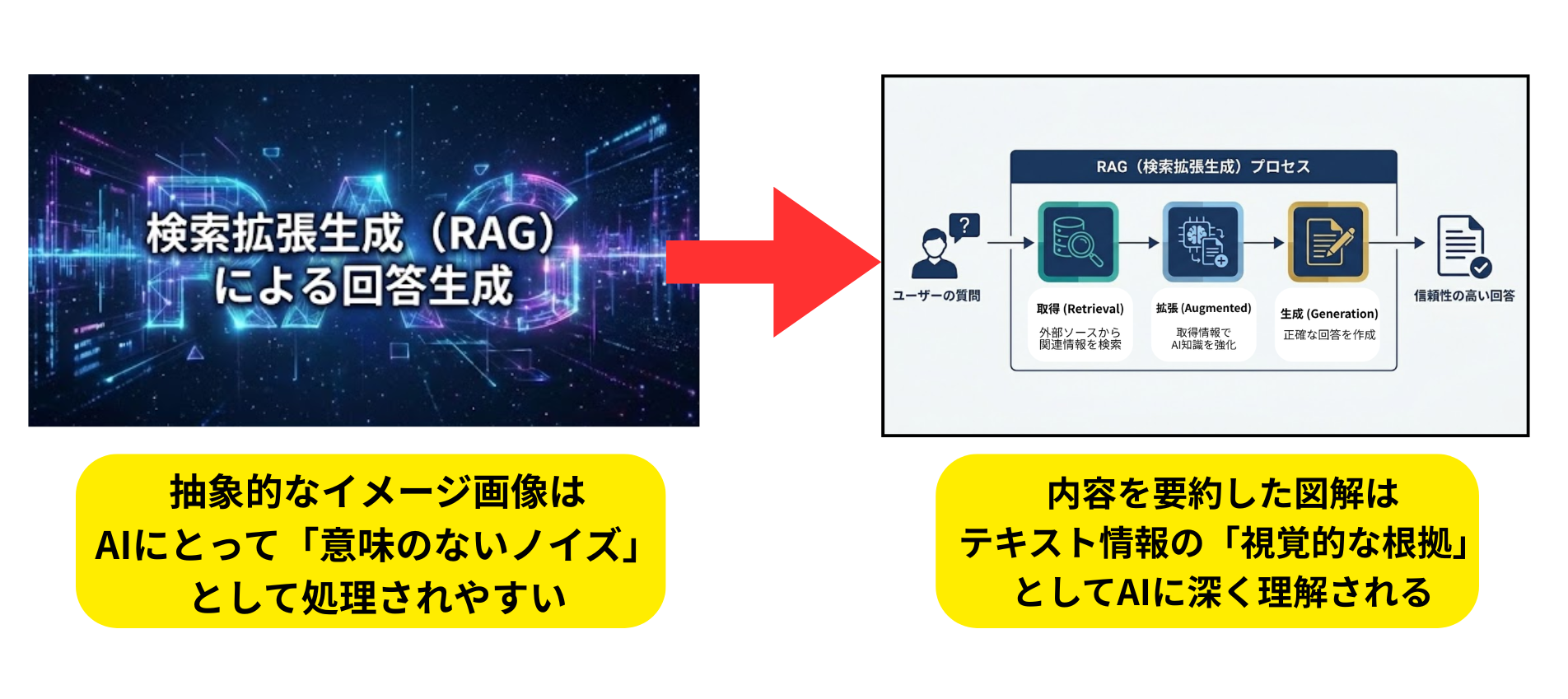
記事に挿入する画像は、単なる「装飾」ではなく、AIに情報を伝えるための「重要なコンテンツ」として扱う必要があります。
これはChatGPTのような現在の主要なAIモデルが、「マルチモーダル化」によって、テキストだけでなく画像の内容も高精度に解析しているからです。
内容と関係のない抽象的なイメージ画像(上図の左)は、AIにとって「意味のないノイズ」として処理される可能性があり、認識されない場合があります。
一方で、この記事の「検索拡張生成(RAG)」の解説でも使用した右の図解のように、情報を要約した画像を配置すると、AIはテキストと画像の整合性を確認し、情報の理解を深めます。
つまり、人間にとって分かりやすい図解は、AIにとっても理解しやすい良質なデータとなります。
記事内の複雑な概念の解説などは、テキストとセットで図解化し、AIに対して「視覚的な根拠」を提示する構成が重要です。
⑧引用情報を詳細に記載する
AIは情報の信憑性を検証する際、その「出典元」が具体的にどこであるかを重視しています。
単に「ある調査によると」と記述するだけでは、AIはその情報の正確性を外部データと照合して評価することができず、引用の優先順位を下げてしまうリスクがあります。
このように情報の「出どころ」を透明化することは、AIから信頼に値するエビデンスとして選ばれるための条件となります。
【Before】引用情報が曖昧な例文
最新の調査によれば、リモートワークを週3日以上実施している企業では、離職率が低下する傾向にあるという結果が出ています。
【After】引用情報が詳細な例文
株式会社〇〇が発表した『2026年度版:働き方の多様性と離職率に関する実態調査(対象:国内企業500社)』によれば、週3回以上のリモートワーク導入企業は、未導入企業と比較して年間離職率が「4.2%」低いという結果が示されました。
※例文のため事実と無関係です。
⑨執筆者・監修者情報を掲載する

AIが情報の信頼性を評価する際、「誰が書いたか」という発信者の実在性と専門性は決定的な判断材料となります。
そのため、記事の冒頭や末尾に「執筆者・監修者のプロフィール」を詳細に掲載することは、LLMOにおいても有効な施策です。
弊社記事においても、上図のような監修者情報を明示しています。
単に会社名を表示するだけでなく「2005年にSEO事業を開始」「累計5,000社以上のコンサルティング実績」といった客観的な数値を明示することが重要です。
これにより、AIは「この記事は信頼できる専門家によって提供されている」と判断しやすくなります。
執筆者や監修者の実績、活動内容、保有資格を具体的に記述することで、AIに「引用すべき権威ある情報源」としてのシグナルを送り、引用率の向上につなげられます。
⑩構造化データを実装する
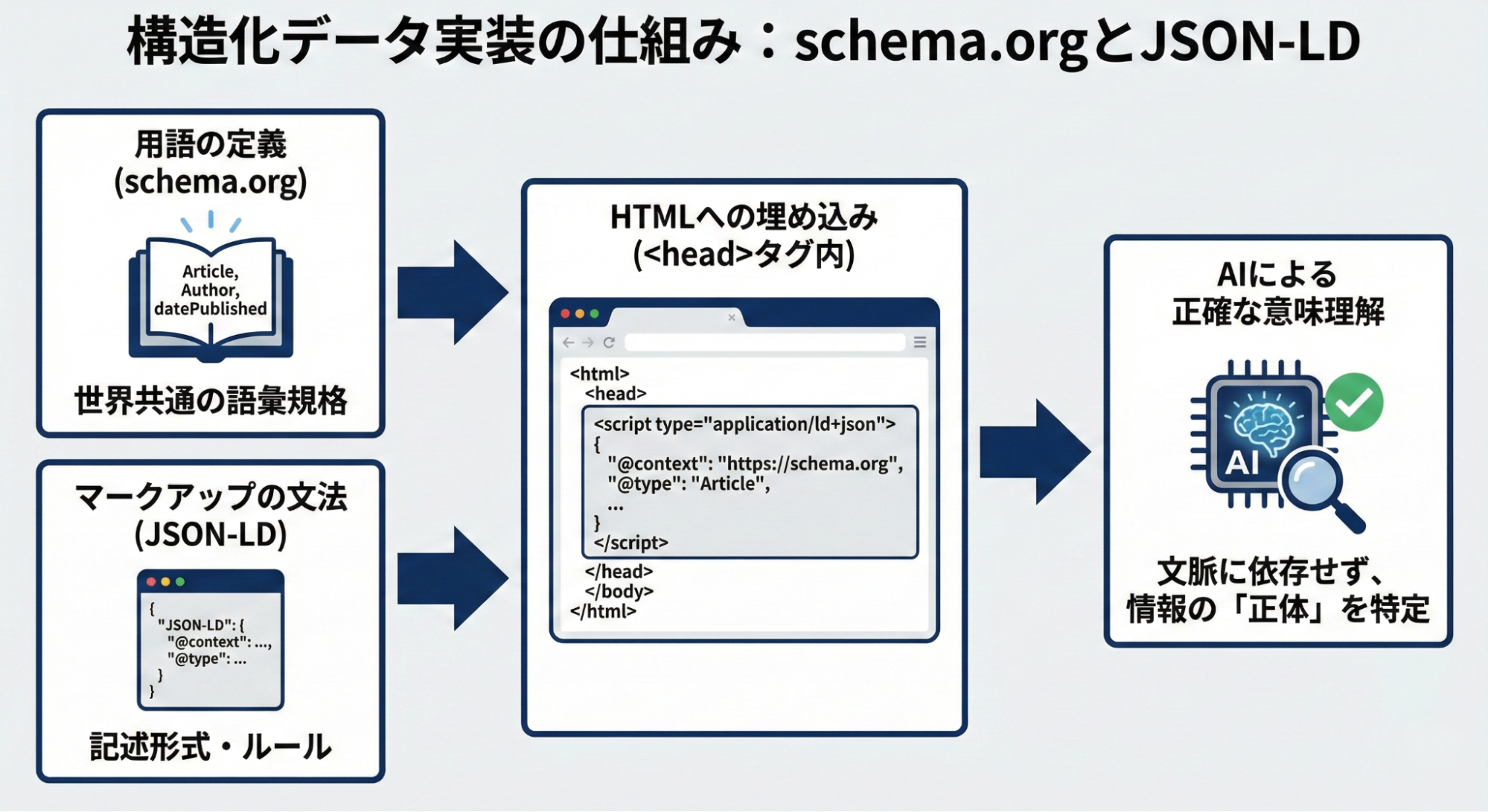
AIにコンテンツの内容を正確に理解させるには、構造化データの実装が不可欠です。
構造化データは、SEOにおいても古くから重要視されてきた要素ですが、AIにおいても必須要素であることが分かっています。
構造化データとは、検索エンジンやAIが情報を解析する際の手助けとなる「専用のラベル」のようなものです。
主に以下の2つの要素で構成されます。
【用語:schema.org】
世界共通の規格である「schema.org」で定義されたボキャブラリーを使用します。例えば、記事全体を指す「Article」、執筆者を指す「Author」、公開日を示す「datePublished」といった単語を用いて、情報の属性を定義します。
【マークアップの文法:JSON-LD】
記述には「JSON-LD」という形式を用いるのが一般的です。これは、HTMLのソースコード内(主にheadタグ内)に、「”name”: “著者名”」といった「キーと値」のセットで書き込む手法です。
このように情報を読み取りやすい形式に整えることで、AIは文脈の推測に頼ることなく、その情報の「正体」を確信を持って特定し、引用につなげることができます。
⑪被リンク・サイテーションを獲得する
AIが情報の信頼性を判断する際、外部サイトからの「被リンク」や「サイテーション(言及)」は、第三者からの客観的な支持を示す強力なシグナルとなります。
特に権威あるメディアや、テーマの関連性が高いサイトからの言及は、AIが自社サイトを「その分野における重要な情報源」として認識するための決定打となります。
単に良いコンテンツを作るだけでなく、能動的に外部からの評価を獲得しにいく姿勢がLLMOには不可欠です。
具体的な獲得手段は、以下の通りです。
- 価値あるニュースを「プレスリリース」として配信し、メディア掲載を狙う
- 他にはない独自の「調査データ」や「一次情報」を公開し、自然な引用を促す
- 業界の専門家と「対談・インタビュー」記事を制作し、相互に紹介し合う
- 業界イベントやウェビナーに「登壇」し、開催レポートなどで言及される
- SNSで有益な情報を発信し、その拡散力でユーザーからの言及を狙う
ChatGPTに引用されない時の考えられる原因

LLMO対策を徹底し、コンテンツの質を極限まで高めても、ChatGPTからの引用が一切発生しないケースがあります。
その場合、ライティングの技術以前に「技術的なアクセス制限」が障壁となっている可能性を疑わなければなりません。
OpenAIは、サイトの情報をChatGPTの回答内に適切に反映させるための条件として、以下のガイドラインを提示しています。
サイトのコンテンツを ChatGPT の要約やスニペットに含めるには、OAI-SearchBot をブロックしていないことを確認してください。必要に応じて robots.txt を更新し、OAI-SearchBot がアクセスできるようにする必要があります。
なお、第三者の検索プロバイダーから許可されていないページの URL を取得した場合や、他のページをクロールする過程で取得した場合でも、そのページがユーザーのクエリに関連しているというシグナルがあると、ChatGPT Atlas ではリンクとページタイトルのみを表示することがあります。
これを望まない場合は、noindex メタタグを使用してください。なお、クローラーがメタタグを読み取るには、該当ページのクロールが許可されている必要があります。
この公式見解から、技術的に「引用を拒絶」してしまっている主な原因として、以下の2点が考えられます。
- robots.txtによる「OAI-SearchBot」のブロック
- noindexメタタグによる「掲載拒否」の設定
まずは、AIが自社サイトを円滑にクロールでき、かつ「掲載を許可する」設定になっているかという技術的な道筋を最優先で確認しましょう。
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
ChatGPTの引用からの流入を確認・測定できるツール

LLMO対策に取り組む上で、多くのマーケターやサイト運営者が懸念するのが「実際にどれだけの流入に繋がっているのか?」という点です。
結論から言えば、ChatGPTからの流入は、従来の検索エンジンからの流入と同様に計測が可能です。
OpenAIは公式に、ChatGPT経由のアクセスには識別用のパラメータが付与されることを明示しています。
ChatGPT は参照 URL に自動的に UTM パラメータ utm_source=chatgpt.com を付与するため、ChatGPT の検索結果からの流入トラフィックを明確に追跡・分析できます。
この仕様により、LLMO対策が単なる「ブランド認知」に留まらず、具体的なコンバージョンやサイト成長にどう寄与しているかを数値で評価できるようになりました。
ここからは、実際にどのようなツールを使ってこの流入トラフィックを可視化していくのか、具体的な測定手法を解説します。
Googleアナリティクス(GA4)
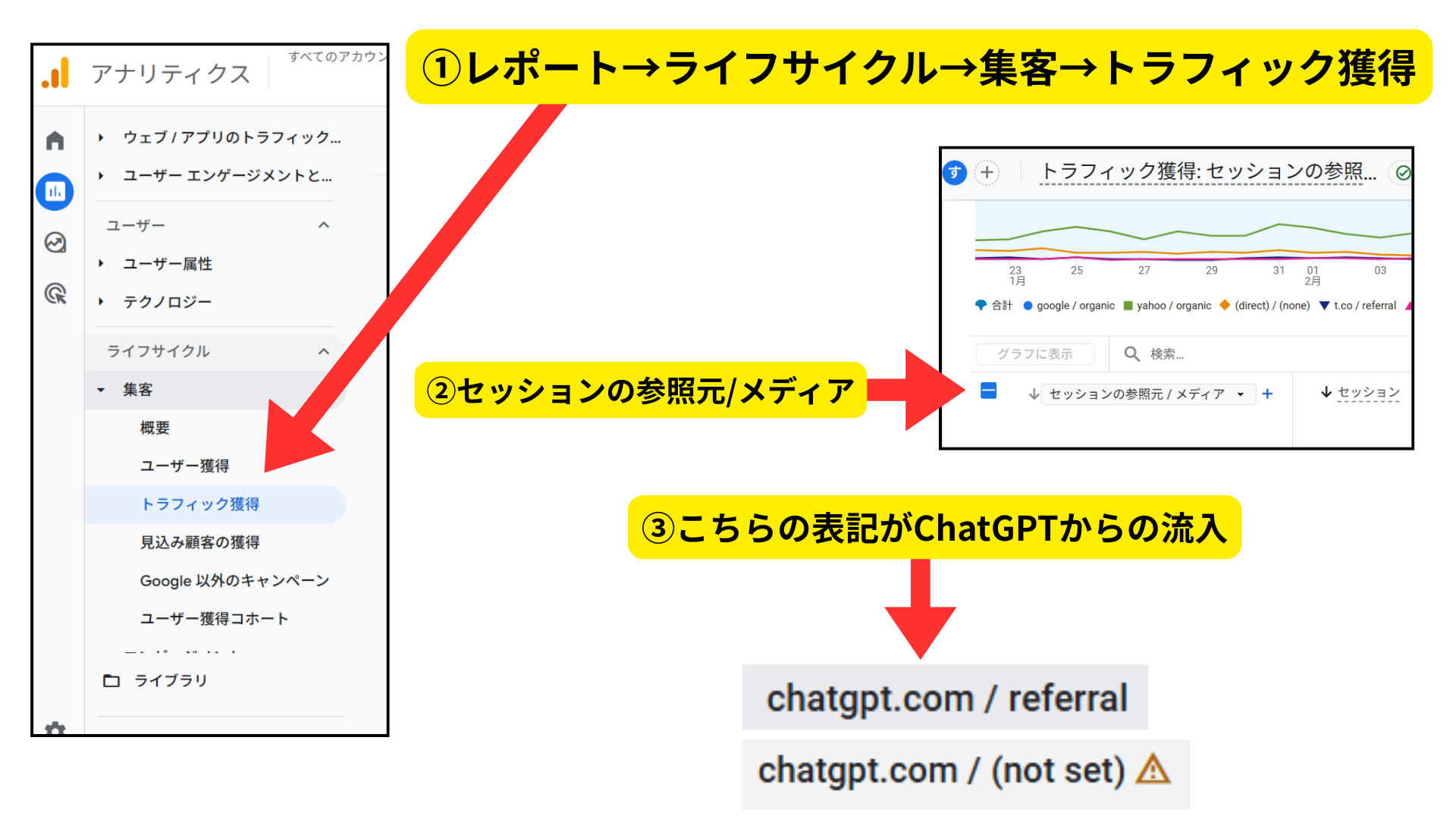
Googleアナリティクス(GA4)では、以下の手順でChatGPTからの流入を測定することが可能です。
- 「レポート」→「ライフサイクル」→「集客」→「トラフィック獲得」の順に移動。
- グラフ下のテーブルを「セッションの参照元/メディア」に変更。
- 一覧に表示された中の「chatgpt.com / referral」の項目が流入数。
「chatgpt.com / (not set)」は、参照元がChatGPTであることは特定できているものの、メディア情報がGA4側で正しく判別できなかった場合に発生するものです。
さまざまな原因が考えられますが、アプリからの流入時に発生しやすいものです。
similarweb
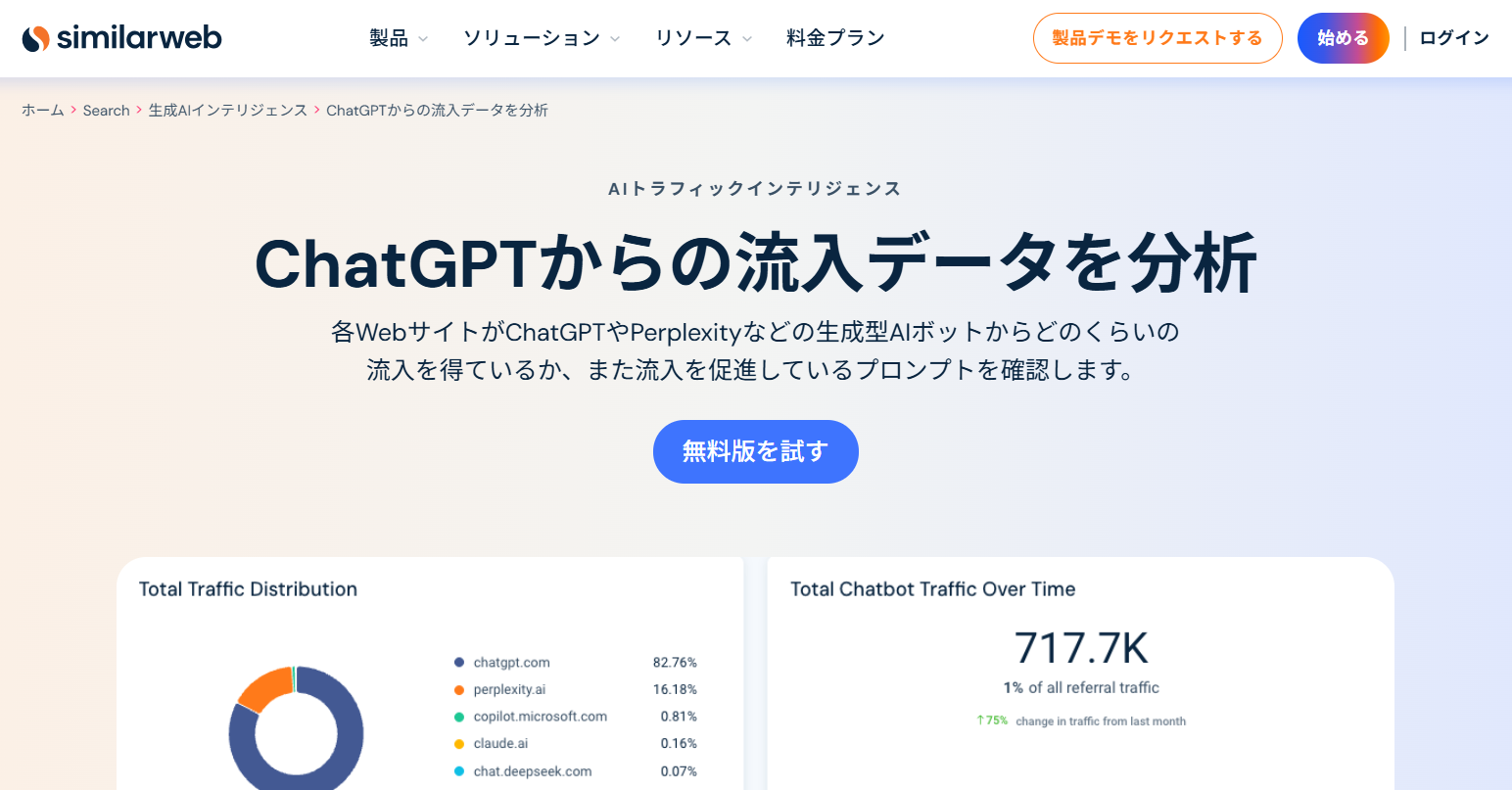
参照:similarweb
自社サイトだけでなく、競合他社や業界全体のAIトラフィック動向をより深く、網羅的に分析したい場合には「Similarweb(シミラーウェブ)」のツールが有効です。
具体的には、以下のような高度な分析が可能です。
- ChatGPT以外の主要AIボット(Perplexity, Claude, DeepSeek等)のトラフィックも網羅。
- ChatGPTの流入のきっかけとなった「プロンプト」を確認できる。
- 競合他社とのAIの認知度や可視性が比較可能。
特に、流入時のプロンプト(具体的な問い)を確認できるのは、今後のコンテンツの改善にも役立てることができます。
有料ツールではありますが、AI検索における「検索意図」を具体的なデータとして可視化できるため、その価値は高いでしょう。
【番外編】指名検索でも成果を評価する
LLMO対策の真の成果は、ChatGPTからの直接的な流入数だけではありません。
AI引用率が高いと、ユーザーは「その会社やブランドをもっと詳しく知りたい」と考え、Googleなどで直接検索を行うようになります。
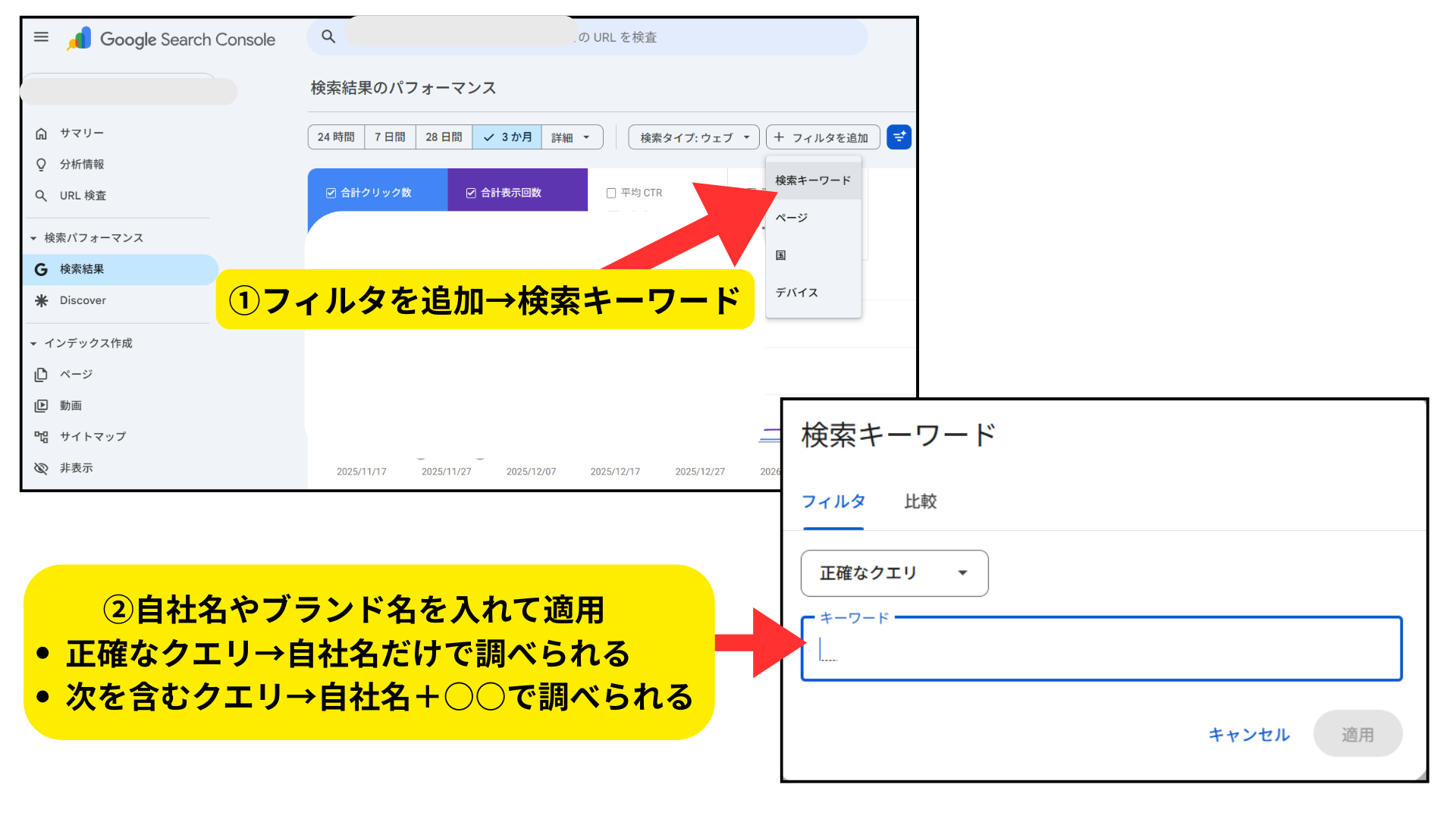
このブランド認知の広がりを測定するために、Google Search Consoleを活用します。
具体的な測定手順は、以下の通りです。(上図参照)
- 「検索パフォーマンス」を開く。
- 「フィルタを追加」から「検索キーワード」を選択。
- 自社名やブランド名を入力して適用。
-
フィルタの設定で以下のように分析可能。
・正確なクエリ:自社名単体での検索数を調べたい時。
・次を含むクエリ:「自社名+口コミ」などの関連キーワードもまとめて調べたい時。
直接的な計測が難しいAI検索において、指名検索数の増加は、自社サイトがAIに引用され、着実にユーザーへ認知されていることを示す証拠となります。
ChatGPTに関する2026年の最新ニュース
AI業界の動向は非常に速く、2026年に入りChatGPTを取り巻く環境にもいくつかの重要な変化が見られます。
市場シェアの推移や、アルゴリズムの傾向、そして新しい収益モデルの導入など、サイト運営者がLLMOを進める上で把握しておくべき3つの最新動向を解説します。
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
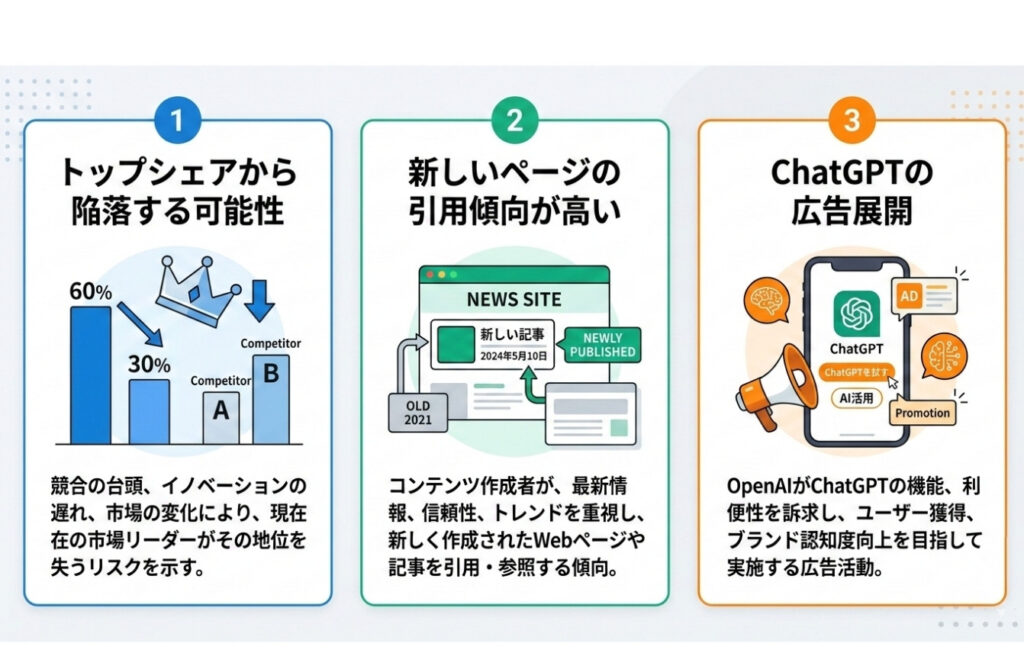
トップシェアから陥落する可能性
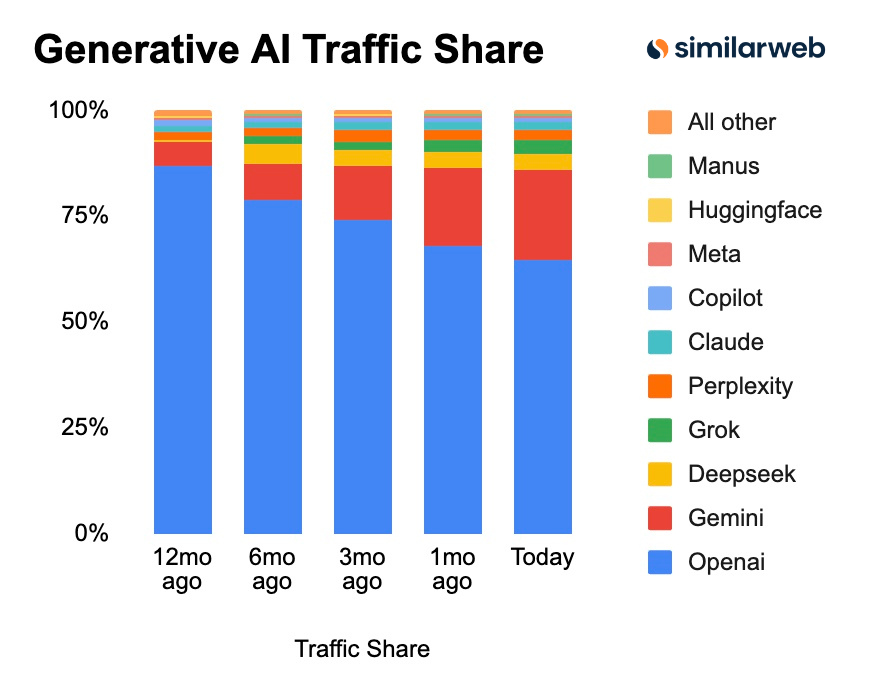
参照:similarweb
これまで市場で圧倒的な占有率を誇ってきたChatGPTですが、2026年に入りその立ち位置に大きな変化が生じています。
similarwebが公開した最新のトラフィックデータによると、1年前には86.7%という極めて高いシェアを維持していたChatGPTですが、現在は64.5%までその数字を落としています。
一方で、急速にシェアを伸ばしているのが、Googleの「Gemini」です。
Geminiのシェアは1年前のわずか5.7%から、直近では21.5%にまで急拡大しました。
この急激な追い上げにより、特定のツールが一強として君臨する時代は終わり、複数の有力なAIが競い合う多極化の時代へと突入しています。
サイト運営者にとっても特定のプラットフォームだけに依存せず、幅広いAIツールを意識した最適化が求められていることを示唆しています。
新しいページの引用傾向が高い
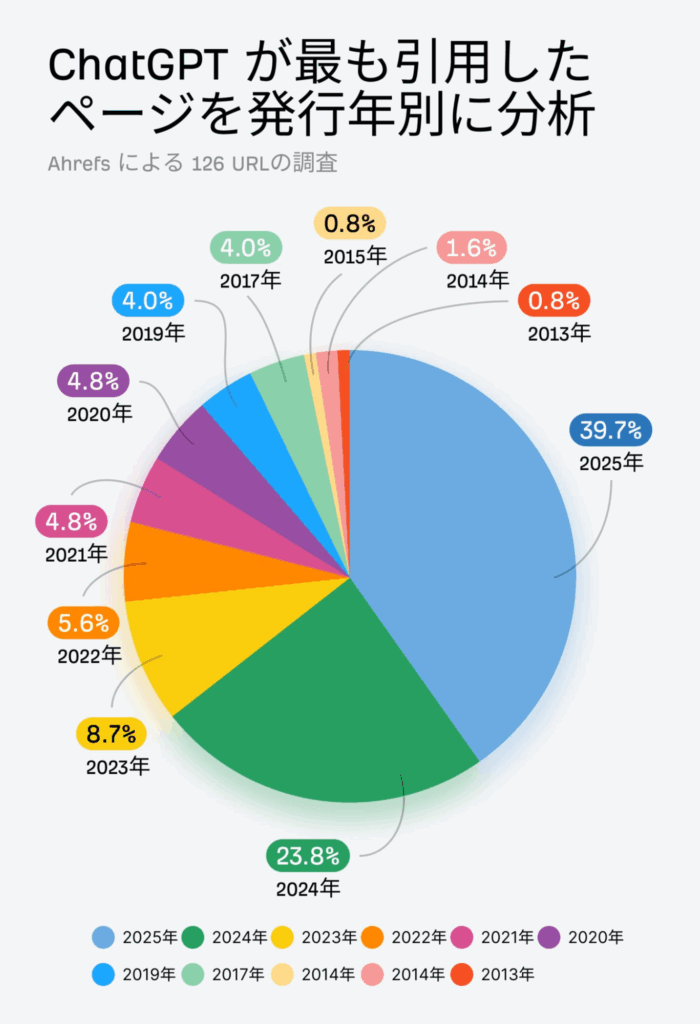
参照:Ahrefs blog
SEOツールで有名な「Ahrefs」の調査によると、ChatGPTが引用するコンテンツの多くが比較的新しいページに集中していることが分かっています。
発行年別の分析において、2025年公開のページが39.7%、2024年が23.8%と、直近のコンテンツが引用の大部分を占めていることが分かります。
分析数は126URLと少ないものの、ChatGPTが新しい情報を好む傾向があることが分かります。
ChatGPTの広告展開
OpenAIは2026年2月9日、米国にて無料版およびGoサブスクリプションプランの成人ユーザーを対象とした広告表示のテストを開始しました。
この新たな広告展開は、AIのデジタルマーケティングに大きな影響を及ぼす可能性があります。
まだ、テスト段階のため仕様が変わるかもしれませんが、現時点(2026年2月)で、以下のことが判明しています。
- 広告は回答の独立性を維持し、通常の回答とは視覚的に区別できる形で表示される。
- 広告主はチャット履歴や個人情報にアクセスできず、ユーザーの会話プライバシーは保護される。
- ユーザーは広告の非表示やデータの削除を自由に行える。
- 18歳未満のユーザーや、健康・政治などの機微なトピックを扱う会話には広告が表示されない。
かつての検索エンジンでは「SEOか、リスティング広告か」という戦略的な判断が求められました。
今後はAI検索の領域においても、「AIの自然引用か、AI広告か」という新たな投資判断が、求められる可能性があります。
ChatGPTのLLMO対策に関するよくある質問(FAQ)
ChatGPTへの最適化を進める上で、現場の担当者が抱きやすい疑問や、実施前に解消しておくべきリスクについてQ&A形式でまとめました。
SEOとの両立や技術的な設定など、実務に直結するポイントを確認しましょう。
Q:SEOはもうやらなくてもいい?
SEOは、LLMOの重要な土台であり、むしろその重要性は増しています。
LLMOとSEOには「構造化データによる情報整理」や「E-E-A-Tの担保」など、いくつかの共通点があります。
AIボットも従来の検索エンジンと同様にウェブサイトをクロールして情報を収集するため、SEOによって整理されたサイト構造や正確なマークアップは、AIが内容を正しく理解する助けとなります。
まずはSEOでサイトの基盤をしっかりと固め、その上でAIが引用しやすい形に最適化(LLMO)を重ねていくことが、AI時代における現在の最適解と言えます。
Q:AIモデルによって対策内容は変わる?
各プラットフォームで引用傾向に若干のムラはありますが、本質的な対策内容はどのモデルでも共通しています。
「構造化データによる情報整理」「結論ファーストの文章」「独自データや一次情報の提供」といったLLMOの核心となる施策は、すべてのAIモデルに共通して有効と考えられます。
これはLLMOが、AIのRAG(検索拡張生成)という信頼できる外部情報を抽出して回答を生成する共通の仕組みに基づいて、対策しているためです。
Q:ChatGPTによる学習・引用を拒否(ブロック)する方法は?
特定のページが誤った文脈で引用され、風評被害を招く可能性がある場合などは、robots.txtという設定ファイルを活用することで、サイト全体へのアクセスを一括で拒否できます。
-
回答時の引用を拒否する場合
User-agent: OAI-SearchBot に対して Disallow: / を指定する。 -
AIモデルへの学習を拒否する場合
User-agent: GPTBot に対して Disallow: / を指定する。
ちなみに、特定のディレクトリだけをブロックすることも可能です。(例: Disallow: /AAAAA/)
これにより、AIがサイト内の情報を読み取ることができなくなるため、不正確な情報の拡散や意図しない要約を防ぐことができます。
【リンク表示も完全に消したい場合】
robots.txtでブロックしていても、外部の検索プロバイダー経由でURLが取得された場合、ChatGPTの回答末尾に「リンクとタイトル」だけが参照として表示されるケースがあります。
これも完全に防ぐには、HTMLのmetaタグに noindex を記述する必要があります。
まとめ:ChatGPTへの引用は「信頼」の証。LLMO対策でブランド価値から流入へ
ChatGPTが膨大なWeb情報の中から、自社サイトを回答の根拠として「引用する」ことは、AI時代における新しい信頼の形を得るようなものです。
最後に、ChatGPTからの引用を勝ち取るための重要ポイントをまとめます。
-
AIに分かりやすい文章
(結論ファースト、一文一結論、指示語の回避、表・箇条書き・図解の活用) -
E-E-A-Tの担保
(一次情報、引用情報で根拠付け、監修者情報) - FAQ・構造化データの実装
- 被リンク・サイテーションの獲得
ChatGPTに選ばれるためのLLMO対策は、結果として、情報を求めるユーザーにとっても「分かりやすいコンテンツ」を提供することにつながります。
