AIO・SEO
AIO・SEOブログ
LLMO対策のやり方を完全解説!AIに引用されるための具体施策と対策事例を紹介
2026.06.01 SEO
この記事の監修SEO会社
株式会社NEXER
2005年にSEO事業を開始し、計5,000社以上にSEOコンサルティング実績を持つSEOの専門会社。
自社でSEO研究チームを持ち、「クライアントのサイト分析」「コンテンツ対策」「外部対策」「内部対策」「クライアントサポート」全て自社のみで提供可能なフルオーダーSEOを提供している。
SEOのノウハウを活かして、年間数百万PVの自社メディアを複数運営。
2026年に入ってから急激に「検索順位はあがっているのに自然検索流入が減っている」企業が増えています。いわゆる「ゼロクリック現象」と言われるもので、それは検索結果におけるAIによる概要の出現やAI検索の利用者増で発生していると言われています。そこで重要になるのが、生成AIから有益な情報参照元として認識されるようにする「LLMO対策」です。
本記事では、LLMO対策の基本から、AIに引用される仕組み、具体施策、優先順位、効果測定、実際の対策事例までをわかりやすく解説します。
この記事を読んで分かること
- LLMO対策とは何か、SEOとの違いや重要視される理由
- ChatGPTやGoogleのAI Overviewsに引用されやすくなる具体的な施策
- 結論ファースト・FAQ構造など、実践的なLLMO対策のやり方
- LLMO対策の優先順位や効果測定方法、よくある失敗例
目次
LLMO対策とは?

- LLMO対策とは、ChatGPTやGoogleのAI Overviewsなどの生成AIに、自社を有益な情報参照元として認識されやすくするための最適化施策
- LLMO対策では、結論ファースト・FAQ形式・E-E-A-T強化など、ユーザーとAIの両者が内容を理解しやすい情報設計が重要
- 生成AIの普及により、従来の自然検索のアクセス数が低下しているため、LLMO対策の必要性が高まっている
LLMO対策とは、ChatGPTやGoogleのAI Overviewsなどの生成AIに自社サイトや自社情報を正しく引用・参照してもらうための対策です。
従来のSEOは「特定のクエリ検索順位を上げること」「オーガニックセッションを増やすこと」が主な目的でした。一方、LLMO対策では、生成AIが内容を理解しやすい構造で情報を整理し、「信頼できる情報源」として認識されることが重要になります。
最近では、「ChatGPTで自社名を検索しても表示されない」「AI Overviewsに競合サイトばかり引用される」といった課題を感じる企業も増えており、SEOに加えてLLMO対策の重要性が高まっています。
LLMO対策の定義
LLMOは「Large Language Model Optimization」の略で、日本語では「大規模言語モデル最適化」と呼ばれます。大規模言語モデル(LLM)を活用した生成AIに対して、情報構造やコンテンツ内容を最適化することを指します。
なお、LLMOと似た用語として「AIO」「GEO」「AEO」などがあります。
GEO(Generative Engine Optimization):生成AI向け最適化(海外で一般的)
AEO(Answer Engine Optimization):アンサーエンジン向け最適化
呼称には違いがありますが、「生成AIに情報を引用・参照されやすくする」という基本的な考え方は共通しているという認識で問題ありません。
LLMO対策はどんなことをおこなう?
LLMO対策の施策は、大きく4つの領域に整理できます。
1つ目は「コンテンツ設計」。ユーザーが読みやすい文章構成になっていることは前提として、結論ファースト、定義文を明示する、FAQ形式で整理するなど、AIが回答として抜き出しやすい構造に作り込みます。
2つ目は「E-E-A-Tの強化」で、経験(Experience)・専門性(Expertise)・権威性(Authoritativeness)・信頼性(Trustworthiness)を高めることでAIから「引用に値する情報源」と認識されやすくなります。
3つ目は「技術的な最適化」。HTML構造の整備や表示速度の改善などです。
4つ目は「外部評価・サイテーション対策」で、自社ブランドの言及をWeb上の信頼できる場所に増やすことで、AIに「広く認知されている信頼できるブランド」と判断されやすくします。
マーケ担当者の方は気づいていると思いますが、これらの施策はいずれもSEO対策で言われてきたことと変わりありません。LLMO対策は「SEOの延長線上にある施策」と捉えるのが実態に近いでしょう。
なぜ今LLMO対策が重要なのか
LLMO対策が注目されている背景には、ユーザーの情報収集行動が「検索エンジン中心」から「生成AI中心」へ変化し始めていることがあります。
これまではGoogle検索で複数サイトを比較するのが一般的でしたが、現在はChatGPTやGoogleのAIモードなどに直接質問し、AIの回答を参考に情報収集するユーザーが増えています。
」どちらが多いですか?.png)
実際、当社が実施した独自アンケート調査では、「AI検索の利用が検索エンジンより多い」と回答した人は35.3%、「AI検索と検索エンジンを半々で使っている」と回答した人は23.5%でした。つまり、約6割のユーザーが、従来の検索エンジンだけに依存しない情報収集行動を取っていることがわかります。
>>【アンケート調査結果】AIが検索を変える時代、BtoBビジネス担当者のLLMOに関する意識・実態調査
また、「AIの回答をきっかけに企業・サービスを知ったことがある」と回答した人は58.8%、「AIの回答を参考に問い合わせ・資料請求をしたことがある」と回答した人は23.5%でした。AIの回答は、すでに企業認知や比較検討、問い合わせ行動にも影響を与え始めています。
さらに、GoogleのAI Overviewsの普及により、AIの回答だけで情報収集を完了する「ゼロクリック検索」も増加しています。当社調査では、「AI Overviewsだけで検索を完結することがある」と回答した人は35.5%でした。
海外論文「Google AI Overviews and Publisher Traffic: Evidence from a Field Experiment」でも、AI Overviews表示時にはオーガニッククリックが38%減少し、ゼロクリック検索の発生率が33%増加したと報告されています。
このように、AI検索はすでに企業の集客やCVに影響を与え始めています。
そのため、ChatGPTやGoogleのAI Overviewsに自社情報がどのように表示・引用されるかを最適化する「LLMO対策」の重要性が高まっているのです。

NEXER Groupは、SEOで培った技術力を活かし、AI検索時代に対応したAIO/LLMO対策を提供しています。
無料分析で課題を可視化し、必要な施策のみを提案。20年以上・5,000社以上のSEO支援実績をもとに、AI Overviews対策や構造化データ実装などを一貫して支援いたします。
AIに引用される仕組みとは?評価ロジックを解説

- 生成AIは「クエリファンアウト」によって、1つの質問を複数の関連クエリに分解し、複数の情報源を横断的に参照しながら回答を生成する。
- AIに引用されやすいコンテンツには、「結論ファースト」「定義文」「FAQ形式」「箇条書き」など、AIが意味を理解しやすい情報構造という共通点がある。
- 一次情報・独自データ・専門性の高いコンテンツは、生成AIから「信頼できる情報源」と評価されやすく、引用率向上につながる。
- 生成AIは単一キーワードではなく、関連トピック全体を横断的に理解するため、周辺疑問まで網羅したコンテンツ設計が重要になる。
- LLMO対策とSEOは評価対象こそ異なるが、E-E-A-T強化やわかりやすい文章作成など、基盤となる施策には多くの共通点がある。
LLMO対策に取り組むなら、まず「AIがどうやって引用元を選んでいるのか」を理解しておきましょう。
AIが情報を選ぶ仕組み
GoogleのAI OverviewsやAIモードでは「クエリファンアウト(Query Fan-out)」という技術が使われています。ユーザーが入力した1つの質問を、AIが内部で複数のサブクエリ(小さな質問)に分解し、並列で検索したうえで結果を統合して1つの回答にまとめる仕組みです。
「LLMO対策とは」という質問なら、内部では「LLMO 定義」「LLMO SEO 違い」「LLMO 具体的な対策」など、関連する複数のサブクエリを自動生成しながら情報を収集します。
この仕組みは、Google自身がAIモード公開時のドキュメントで明言しており、AIモードは「クエリ・ファンアウト」手法を用い、関連する複数の検索を同時に実行してサブトピックやさまざまなデータソースから情報を集約すると説明されています。
ここから導かれる重要な示唆は、「単一キーワードで1位を取る」というSEOの戦い方が相対的に弱くなるという点。代わって、1つのテーマに関する関連する疑問に、1つの記事やサイト全体で網羅的に答えられるかどうかが、引用されるかを左右するようになります。
実際、ChatGPTやGeminiなどの生成AIでも、内部でサブクエリを生成しながら情報収集を行う仕組みが採用されています。
引用されやすいコンテンツの特徴
クエリファンアウトの仕組みを踏まえると、AIに引用されやすいコンテンツには共通する特徴があります。
1つ目は、結論や定義が明確に書かれていること。「〇〇とは△△である」という定義文の形式や、見出し直後に結論を簡潔にまとめるスタイルは、AIが回答として抜き出しやすい構造になります。
2つ目は、FAQ形式や箇条書きで情報が整理されていること。生成AIはもともとユーザーの質問に答える仕組みなので、Q&A形式のコンテンツは構造的に親和性が高くなります。
3つ目は、情報の信頼性が高いこと。一次情報や独自データ、公的機関の引用が含まれていると「裏付けのある情報源」と評価されやすくなります。医療や金融などのYMYL領域では、この信頼性の重みがさらに増します。
4つ目は、テーマに対する網羅性。AIが複数のサブクエリを生成する以上、1つの大きなテーマに対して周辺の疑問まで丁寧に答えているコンテンツのほうが、複数のサブクエリで引用される可能性が高まります。
SEOとの評価ロジックの違いと関係性
LLMO対策とSEOは、評価対象や目的が異なる一方で、基盤となる施策には多くの共通点があります。
| 項目 | SEO | LLMO |
|---|---|---|
| 対策対象 | Google・Bingなどの検索エンジン | ChatGPT・Gemini・AI Overviewsなどの生成AI |
| 目的 | 検索結果で上位表示すること | AI回答内で引用・参照されること |
| 主な流入経路 | 検索結果からのクリック | AI回答経由のリンク流入・ブランド認知 |
| 主な評価軸 | キーワード関連性・被リンク・検索順位 | 情報の信頼性・引用されやすさ・ブランド言及 |
SEOは「検索順位の最適化」、LLMOは「生成AIへの最適化」という違いがあります。しかし、実際には両者で重視される施策は大きく重なっています。
例えば、以下はSEOとLLMOの両方に効果があります。
・コンテンツの網羅性向上
・一次情報の充実
・サイトの専門性強化
実際、AI Overviewsで引用されるサイトには、検索順位やドメイン評価が高いサイトが多いことも複数の調査で指摘されています。
そのため、LLMO対策はSEOを置き換える施策ではありません。まずSEOによって検索エンジンから評価される土台を作り、その上で「生成AIに引用されやすい情報設計」を追加していくことが重要です。
つまり、LLMO対策は「やること自体はSEOで言われてきたことと大きく変わらない、現実的な施策」と考えるのが実態に近いでしょう。
基本的な考えとして、AIとユーザーを明確に分類すべきではありません。
私は、ユーザーにとって理解できる内容が転じてAIにも有効であると考えています。
ただし、そこにはロジックがあり、そこをLLMO対策だと主張しているとも言えます。
具体的には「一次情報」や「明確な数値」、「認識のブレがない表現」などです。
これらは、ユーザーにとっても必要な情報だということが理解できるはずです。
LLMO対策の具体的な方法一覧

LLMO対策は「コンテンツ設計」「E-E-A-T強化」「技術的最適化」「外部対策」の4領域に分けて取り組みます。
それぞれの領域で何をすべきかを、具体的な手順と判断基準まで掘り下げて解説します。
| 領域 | 主な施策 | 難易度 | 効果が出るまでの目安 |
|---|---|---|---|
| コンテンツ設計 | 結論ファースト・FAQ | 低 | 1〜3ヶ月 |
| E-E-A-T強化 | 一次情報・独自データの公開、著者情報整備 | 中 | 3〜6ヶ月 |
| 技術的最適化 | HTML構造・表示速度改善 | 中 | 1〜3ヶ月 |
| 外部対策 | サイテーション獲得・メディア露出 | 高 | 6ヶ月〜 |
コンテンツ設計(結論ファースト・FAQ構造)
AIに引用されるコンテンツを作るうえで、最初に手をつけるべきはコンテンツの「型」の見直しです。
AIは文章を意味のかたまりで取り込み、ユーザーの質問に合致するかたまりを抜き出して回答に使います。
つまり「AIが切り取りやすい形」で書いてあるかどうかが、引用されるか否かを大きく左右するのです。
具体的な手順は次の2つに分けられます。
②FAQ形式の整備
1つずつ詳しく説明します。
①結論ファーストへの書き換え
見出し直後の1〜2文に、その見出しに対する「結論」「定義」を入れます。「〇〇とは△△である」「結論から言うと、〇〇です」というシンプルな構文が理想です。
AIは見出し直下のテキストを優先的に「答え」として認識する傾向があるため、ここに結論がないと、本来引用されるべきコンテンツが見逃されることになります。

| 例 | 内容 |
|---|---|
| 良い例 | 「LLMO対策とは、生成AIの回答に自社サイトが引用されやすくなるよう最適化する施策です。」 |
| 悪い例 | 「近年、生成AIの普及にともない、Webマーケティングの世界では新たな潮流が生まれています。その一つが…」 |
実際の現場では、「検索流入が多い記事」「CVに近い記事」「AI Overviewsが出やすいキーワードの記事」から優先的に修正していきます。
特に比較記事・定義記事・ランキング記事は、AIが冒頭の結論部分をそのまま引用するケースが多いため、最初に改善効果が出やすい領域です。
一方で、コラム色の強い記事は、結論ファーストを入れすぎると読みにくくなる場合もあります。実務では「AIに伝える構造」と「人間が読みやすい流れ」のバランスを調整することが重要になります。
②FAQ形式の整備

生成AIは「ユーザーの質問に答える」ことを目的としたツールです。
そのため、Q&A形式で書かれたコンテンツは構造的にAIに引用されやすくなります。
記事末尾のFAQセクションに、想定質問を5〜10個並べておきましょう。
質問の選び方のコツは、「Googleサジェスト」「関連検索」「People Also Ask」「ChatGPTに”〇〇についてよくある質問を教えて”と聞く」の4つを組み合わせることです。
実際にユーザーが投げかける質問の集合に近づくほど、AI回答での引用機会が増えます。
「〇〇とは」「〇〇の違い」「〇〇は意味ない?」「〇〇と△△どっちがいい?」のような比較・定義・判断系の質問を優先して追加しています。
特にChatGPTでは、「初心者向けに説明して」「おすすめを教えて」といった会話型の質問が増えているため、自然文に近いFAQを意識しています。
一次情報・独自データの活用(E-E-A-T強化)
AI時代において、E-E-A-T(Experience:経験/Expertise:専門性/Authoritativeness:権威性/Trustworthiness:信頼性)はSEO以上に重要な評価軸になっています。
なぜなら、AIは「どこの誰が書いた情報か」「裏付けがあるか」を強く意識して引用元を選んでいるからです。
E-E-A-Tを強化する施策は、優先度の高い順に次の3つです。
| 施策 | 具体内容 | 目的 |
|---|---|---|
| ①著者情報・運営者情報の整備 | 顔写真・経歴・専門分野・会社概要を明示 | 信頼性向上 |
| ②一次情報の発信 | 独自調査・アンケート・比較検証を公開 | 独自性向上 |
| ③外部評価の可視化 | 受賞歴・掲載実績・登壇歴を掲載 | 権威性向上 |
①著者情報・運営者情報の徹底整備
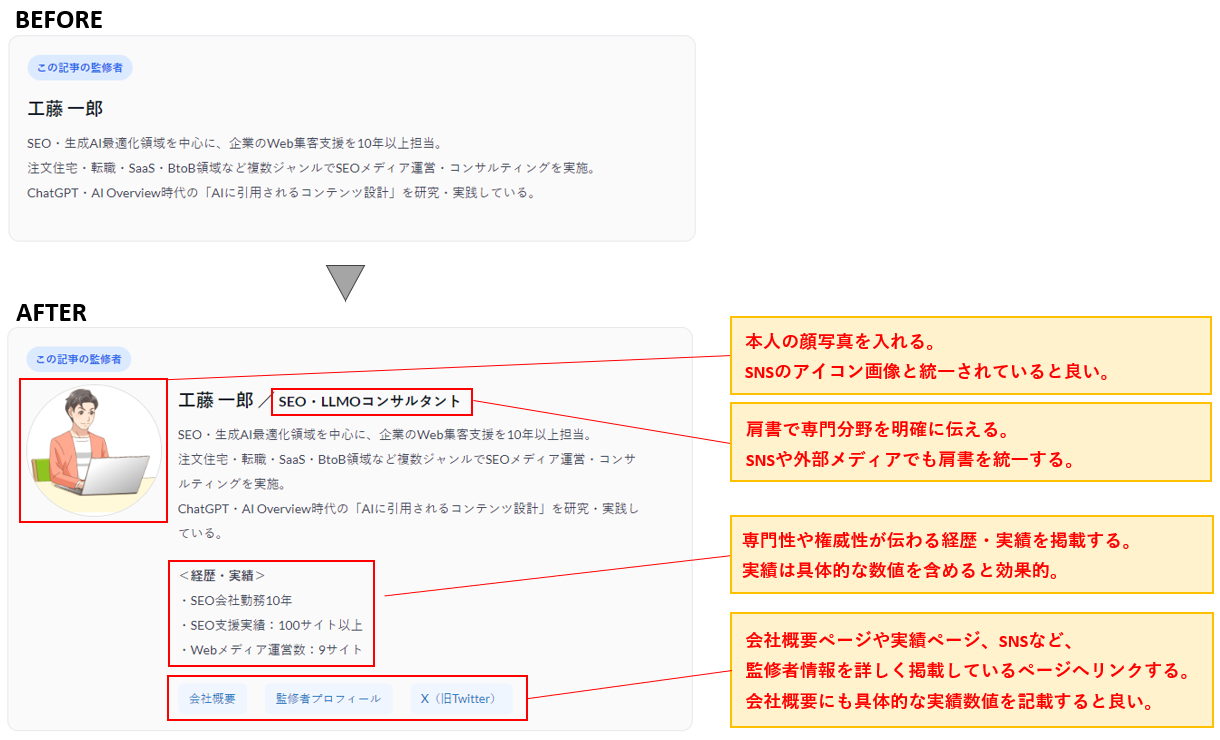
記事の冒頭または末尾に、著者の顔写真・氏名・経歴・専門分野・SNSリンクを必ず明示します。
法人サイトの場合は会社概要ページに、設立年・代表者・事業内容・所在地・取引実績などを具体的な数値とともに記載します。
「20年の実績」「導入企業5,000社」のような数値情報は、AIが信頼性を判断するうえで重要な手がかりになります。
監修者や運営者情報は、「本当にその分野の専門家か」明確にわかるように記載しましょう。
実績ページやSNSなど、必要なリンクを掲載し、「誰が見ても専門家だと納得できる」ことが理想です。
もし記事作成者が専門家ではない場合、周りで一番の専門家に、記事を監修してもらうと良いでしょう。
その場合は、単に監修者として載せるだけではなく、本文に「専門家のアドバイス」のような、コメントを載せると良いです。
②一次情報の発信
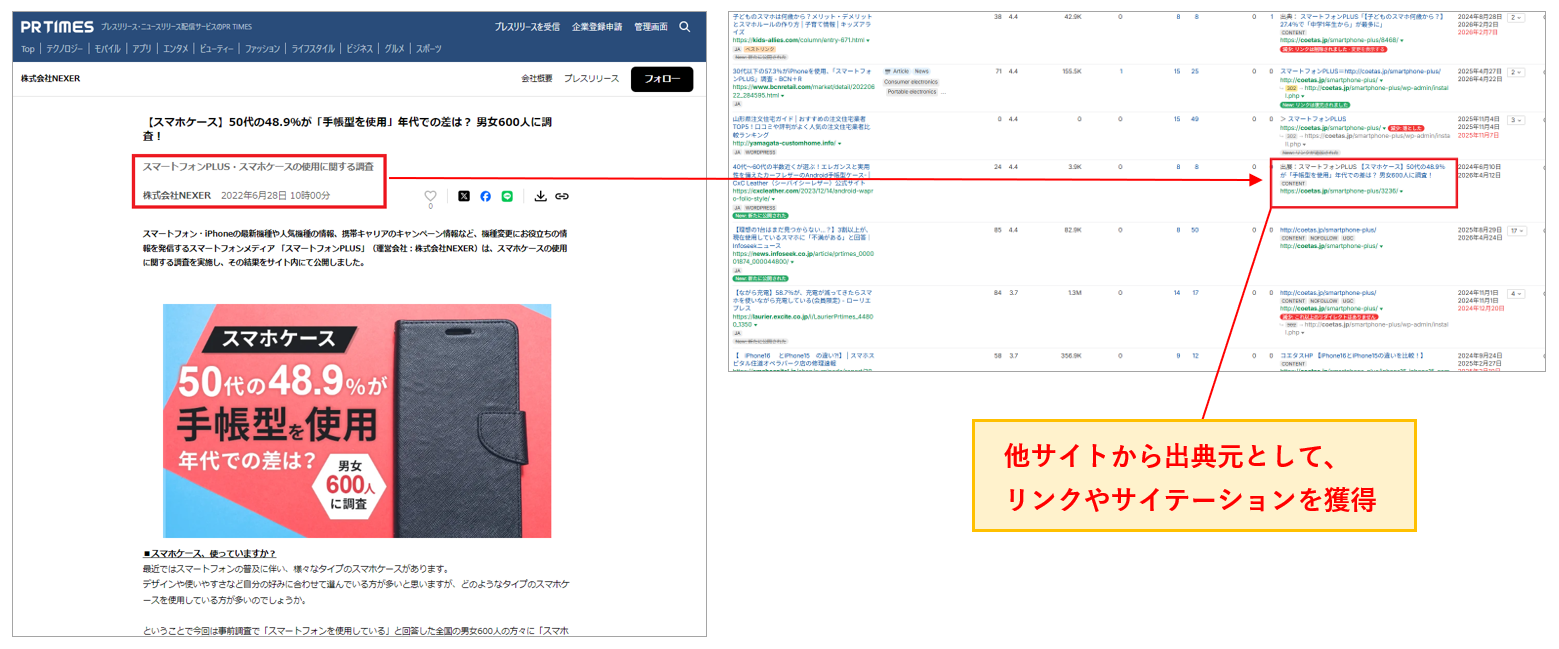
他サイトの引用ばかりで構成されたコンテンツは、AIから見ると「他で代替可能な情報」です。
逆に自社で実施したアンケート結果、現場での失敗談、独自の比較検証データなどは、唯一無二の情報源としてAIに引用されやすくなります。
一次情報の作り方は思っているよりシンプルです。たとえば次のような切り口があります。
・自社の業務で蓄積した内部データ(成約率、CVR、平均期間など)を匿名化・統計化して公開する
・業界の競合サービスを実際に試用し、機能比較表を作成する
・社内エキスパートへのインタビューを記事化する
一次情報というと大規模調査をイメージしがちですが、実務では小規模アンケートでも十分差別化になります。
実際には、10〜30件程度のユーザーアンケートでも、「自社独自データ」としてAIに引用されるケースは珍しくありません。
特に「実際にやってみた」「比較検証した」「何件分析した」のような実体験ベースの情報は、生成AIが引用元として扱いやすい傾向があります。
③外部評価の可視化
第三者から評価されている事実は、強力なE-E-A-Tシグナルになります。プレスリリース、メディア掲載実績、業界アワード受賞歴、登壇イベント一覧などを、運営者情報や著者プロフィールに記載しておきましょう。
| E-E-A-Tの要素 | 具体的な施策例 |
|---|---|
| Experience(経験) | 現場での実体験談、ビフォーアフター事例、失敗談の公開 |
| Expertise(専門性) | 資格・学歴・経歴の明示、専門分野に絞った継続発信 |
| Authoritativeness(権威性) | メディア掲載、業界アワード、書籍出版、登壇実績 |
| Trustworthiness(信頼性) | 運営者情報・著者プロフィール・引用元の明示、SSL対応 |
実務では、受賞歴や掲載実績を「会社概要ページだけ」に置いているケースが多いですが、記事下プロフィールやサービスページにも分散して掲載するほうが効果的です。
AIはページ単位で情報を理解しているため、「このページを書いている人・会社の実績」が近くにあるほど、信頼性シグナルとして伝わりやすくなります。
技術的最適化
技術的な最適化も、あわせておこないましょう。
| 技術的施策 | 具体内容 | 目的 |
|---|---|---|
| HTML構造のセマンティック化 | hタグ・pタグ・ul/ol・tableを適切に使用 | AI・検索エンジンの理解向上 |
| 表示速度改善 | Core Web Vitals改善 | UX改善・SEO基礎強化 |
| モバイル対応 | レスポンシブ化・文字サイズ最適化 | モバイルUX向上 |
| クロール最適化 | sitemap.xml送信・robots設定 | クロール効率改善 |
これらは「やらないと減点される基本動作」です。SEOで上位を取る前提条件であり、AIに引用されるための土台でもあります。
お客様のサイトを調査すると、表示速度が極端に遅い、見出しタグの構造が崩れている、モバイルで読みにくいといった基本的な問題が残っているケースも少なくありません。
どれだけ良いコンテンツを作っても、検索エンジンやAIが内容を正しく理解できなければ評価されにくくなります。
そのため、まずはユーザーが快適に閲覧できる状態を整え、その上でコンテンツの品質向上に取り組むことが重要だと考えています。
外部評価・サイテーション対策
自社サイト内をどれだけ磨き込んでも、外部からの評価がなければAIは「業界で信頼されている情報源」とは判断しません。そこで必要なのが、他のサイトからのサイテーションや被リンクによる外部評価です。
サイテーションとは、他のWebサイト・SNS・レビューサイトなどでの自社や自社サービスへの言及のことです。被リンクとの違いは「リンクがなくてもよい」点で、ブランド名やサービス名がテキストとして登場するだけで、AIにとっては評価の材料になります。
サイテーション対策は、自社の存在感をWeb上に分散して配置していく長期戦の施策です。
具体的な施策は、優先度の高い順に次の4ステップで進めるのが現実的です。
ステップ1:自社情報の正規化(NAP統一)
最初にやるべきは、Web上に散らばっている自社情報の「表記揺れ」をなくすことです。
NAP(Name:社名/Address:住所/Phone:電話番号)が、コーポレートサイト・SNSプロフィール・Googleビジネスプロフィール・各種ディレクトリで完全に一致しているかを確認します。表記が揺れていると、AIは「同じ会社」と認識できず、サイテーションが分散してしまうのです。
ステップ2:レビュー・口コミ獲得
BtoBならITreview、BOXIL SaaS、Capterra(海外向け)、G2など、BtoCなら食べログ、Googleレビュー、価格.comなど、業界に応じたレビューサイトでの存在感を作ります。
レビュー件数と平均評価は、AIが推薦リストを作る際の重要な判断材料です。
ステップ3:業界メディア・専門メディアへの露出
業界特化型のメディアに記事を寄稿したり、インタビュー記事に登場したりすることで、ドメイン評価の高いサイトからの言及を獲得します。
プレスリリース配信サービス(PR TIMES、@Press、共同通信PRワイヤーなど)の活用も、初動として効果的です。
ステップ4:SNS・コミュニティでの継続的な発信
X(旧Twitter)、LinkedIn、業界特化のオンラインコミュニティで、専門家としての発信を継続します。
SNS投稿そのものをAIが引用するケースは限定的ですが、SNSで認知が広がるとサイト名指しでの検索やリンクが増え、結果としてAIに「業界で話題の存在」と認識されやすくなります。
| サイテーションの種類 | 具体例 | AIへの影響度 |
|---|---|---|
| レビューサイト | ITreview、BOXIL、Googleレビュー | 高 |
| 業界メディア | MarkeZine、Web担、ferret | 高 |
| プレスリリース | PR TIMES、@Press、共同通信PRワイヤー | 中 |
| SNS | X、LinkedIn、note | 中 |
| Wikipedia | 企業・人物ページ | 高(掲載難易度は高い) |
特にBtoBビジネスでは、ITreviewやBOXIL SaaSのレビュー件数・評価が、AIの推薦リスト形成に直結します。
「リンクを獲得する」だけでなく「言及される機会を増やす」「業界内での話題性を作る」という視点で外部対策を捉え直すと、施策の優先順位が見えてきます。
実務では、「被リンク獲得」だけでなく「ブランド名の自然言及」を重視するケースが増えています。
特に生成AIは複数ソースを横断して情報を集約するため、「業界内で頻繁に名前が出てくるか」が重要になりつつあります。
一例として、弊社では専門分野のアンケート調査をおこない、プレスリリースで公開することで、業界内に一次情報を拡散し、引用や言及を増やす取り組みをおこなっています。
明確に効果があったと実感しているのは、コラムとプレスリリース施策ですね。
どちらもそうですが、AIに対して「自分たちは有益な情報を提供しているサイトですよ」と、PRすることができる現状においては非常に有効な施策ですし、資産として残ることも大きなポイントです。
NEXER Groupは、SEOで培った技術力を活かし、AI検索時代に対応したAIO/LLMO対策を提供しています。
無料分析で課題を可視化し、必要な施策のみを提案。20年以上・5,000社以上のSEO支援実績をもとに、AI Overviews対策や構造化データ実装などを一貫して支援いたします。
LLMO対策の優先順位!何から始めるべきか

- まずやるべきなのは、「結論ファースト化」や「FAQ形式」の導入など、既存コンテンツをAIが理解しやすい構造へ改善すること
- 次に優先したいのは、E-E-A-T強化や自社独自データ(一次情報)の拡充。
- 優先度が低い施策は、「構造化データの実装」と「チャンク最適化」。
「対策の種類が多すぎて、どこから手をつければいいかわからない」。ここでつまずく方が多いので、優先順位を整理します。
まずやるべき対策
最優先で取り組むべきは「既存コンテンツの結論ファースト化」と「FAQ形式の導入」です。
新しい記事を作るより、すでに公開しているコンテンツを見直すほうがコストパフォーマンスは高くなります。
並行して、運営者情報・著者情報の充実、お問い合わせフォームや会社概要ページの整備、SSL対応の確認など、E-E-A-Tの基本部分もすぐに見直せます。
検索順位がまだ低いキーワードがあればSEOの基本対策で順位を上げることも結果的にLLMO対策につながります。
AI Overviewsで引用されるサイトは検索順位やドメイン評価が高い傾向があるためです。
次にやるべき対策
基本が整ったら、次は自社独自データ(一次情報)の作成に取り組みましょう。
独自データの作成は、すぐに成果が出る施策ではありませんが、中長期的に大きな差別化要因になります。
自社で実施したアンケート調査、業界動向レポート、導入事例の数値化など、自社にしか出せない情報を1つでも公開していきましょう。
一次情報は、生成AIからも「唯一無二の情報源」として引用されやすくなります。
優先度が低い施策
逆に、生成AI検索のためにわざわざ取り組む必要のない対策もあります。
Googleは公式ブログGoogle Search Centralのドキュメント「Google 検索の生成 AI 機能向けにウェブサイトを最適化する」の中で、生成AI検索に表示されるために特別に行う必要のない施策を明示しました。
ここでは、その中でも特に話題になりやすい3つを紹介します。
「llms.txt」の設置
llms.txtは、生成AIに対してWebサイトの構造や重要情報を伝えるためのテキストファイルとして提案されているものです。
しかしGoogleは、生成AI検索に表示されるために、新たにAI向けのファイルやマークアップ、Markdownを用意する必要はないとしています。
2026年時点でも標準仕様は提案段階にとどまり、OpenAI・Google・Anthropicといった主要な生成AIプロバイダーからの公式対応も表明されていません。
Googleのジョン・ミューラー氏もreddit上で「現在、主要なAIシステムでllms.txtを読み込んでいるものはない」という旨を発言しており、現時点で設置による効果は期待できません。
コンテンツのチャンク化
「AIが理解しやすいように」とコンテンツを細かく分割(チャンク化)する必要はありません。
Googleは、自社のシステムは1ページ内に複数のトピックがあってもそのニュアンスを理解し、関連する部分をユーザーに表示できると説明しています。
理想的なページの長さというものは存在しないため、AIのためにわざわざ短く区切るのではなく、読み手にとって分かりやすい構成を優先すれば十分です。
構造化データへの過度な注力
Googleは、生成AI検索に構造化データは必要ないと明言しています。ただし、構造化データはGoogle検索のリッチリザルトの対象となる助けになるため、SEO施策全体の一部としては引き続き有効です。
「AIに引用されるための必須対策」ではない、という位置づけで捉えておきましょう。
これらに共通するのは、いずれも「AIのためだけ」の特別な作業だという点です。
Googleが重視しているのは、AI向けの小手先の対策ではなく、ユーザーにとって価値のある高品質なコンテンツです
基本の対策に集中することが、結果的にAIに引用される近道になります。
「コンテンツのチャンク化」や「構造化データの設置」そのものが悪いわけではありません。
あくまで、AI検索対策だけを目的に実施する必要はないということです。
例えば、コンテンツのチャンク化は、ユーザーが内容を理解しやすいように情報を整理し、文章を区切るために行うものです。
その結果として、内容が明確で読みやすくなれば、SEOにもLLMOにもプラスに働く可能性があります。
これだけやればOK!LLMO対策チェックリスト
最初のステップとして、以下のチェックリストで自社サイトを点検してみてください。
| カテゴリ | チェック項目 | チェック |
|---|---|---|
| コンテンツ | 見出し直下に結論・定義が書かれているか | □ |
| コンテンツ | FAQ形式のセクションがあるか | □ |
| E-E-A-T | 運営者情報・著者情報が明示されているか | □ |
| E-E-A-T | 一次情報や独自データが含まれているか | □ |
| E-E-A-T | 引用元・参考文献が明示されているか | □ |
| 技術 | ページ表示速度は遅くないか | □ |
| 技術 | HTMLタグが意味に沿って使われているか | □ |
| 外部 | 業界メディアやレビューサイトに掲載されているか | □ |
| 外部 | SNSでの情報発信が継続されているか | □ |
すべてを一度に達成する必要はありません。チェックがつかなかった項目から優先的に対応していきましょう。
LLMO対策の効果測定方法

施策をおこなったら効果を測定し、次の改善に活かしていきます。
AI経由流入の測定方法(GA4)
GA4を使えば、生成AI経由でサイトに訪れたユーザーの数を計測できます。
基本は、参照元(リファラー)に生成AIのドメインが含まれているセッションを抽出する方法です。
ChatGPTからの流入は「chatgpt.com / referral」、Geminiは「gemini.google.com / referral」、Perplexityは「perplexity.ai / referral」、Copilotは「copilot.microsoft.com / referral」のように表示されます。
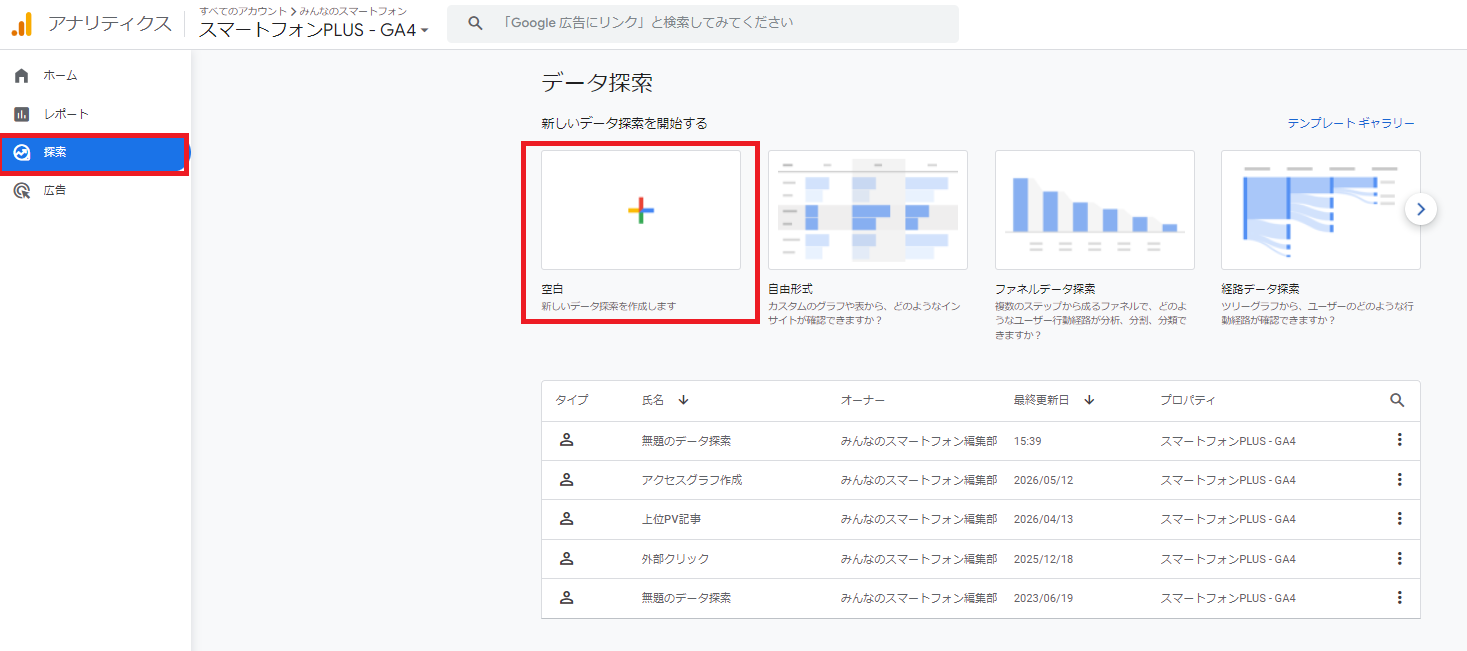
具体的な探索レポートの設定手順は次のとおりです。
手順1. GA4の左メニューから「探索」を開き「空白」を選択する
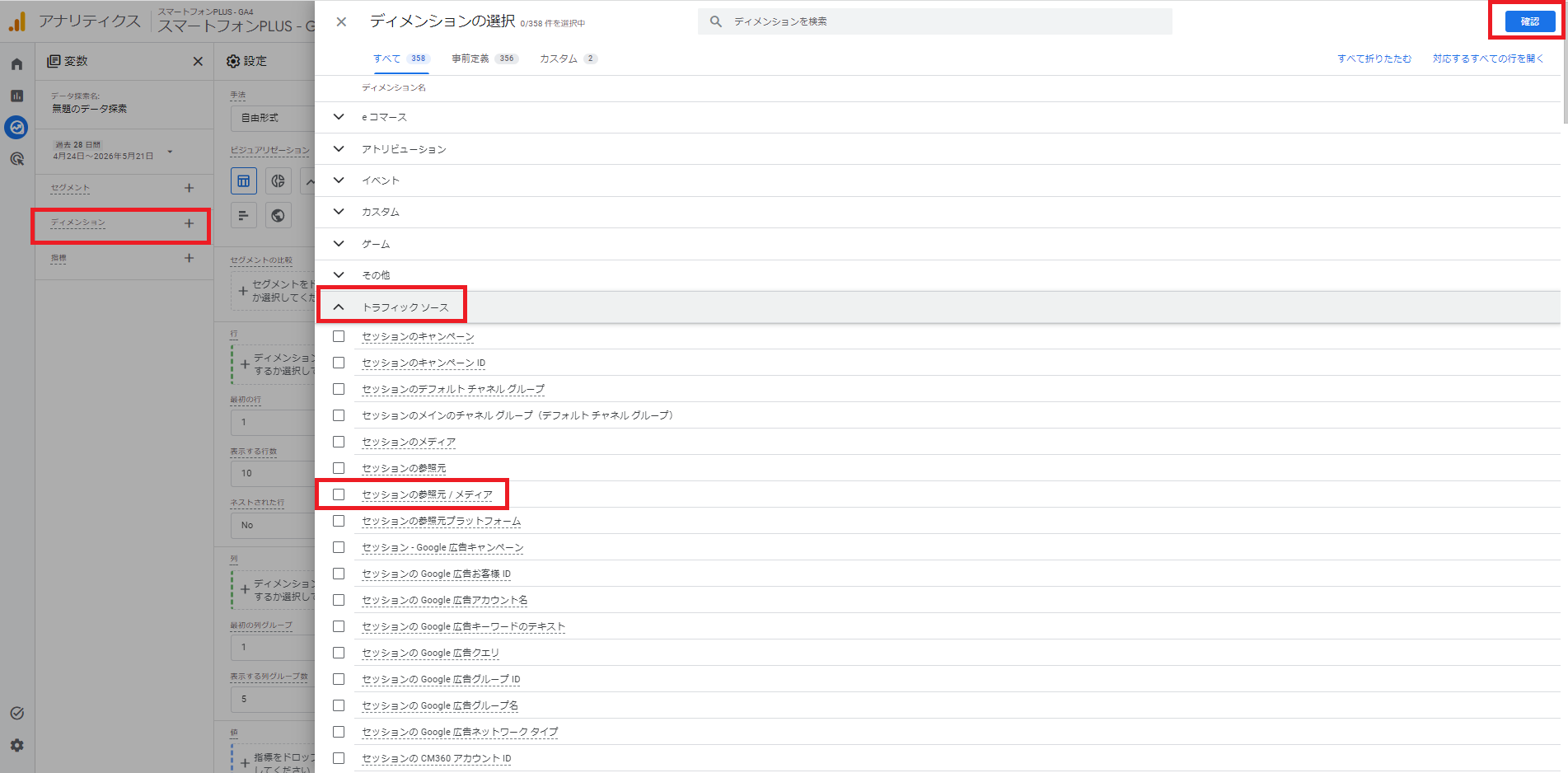
手順2. 変数のディメンションに「セッションの参照元 / メディア」を追加する
手順3. 変数の指標に「セッション」や「総ユーザー数」を追加する
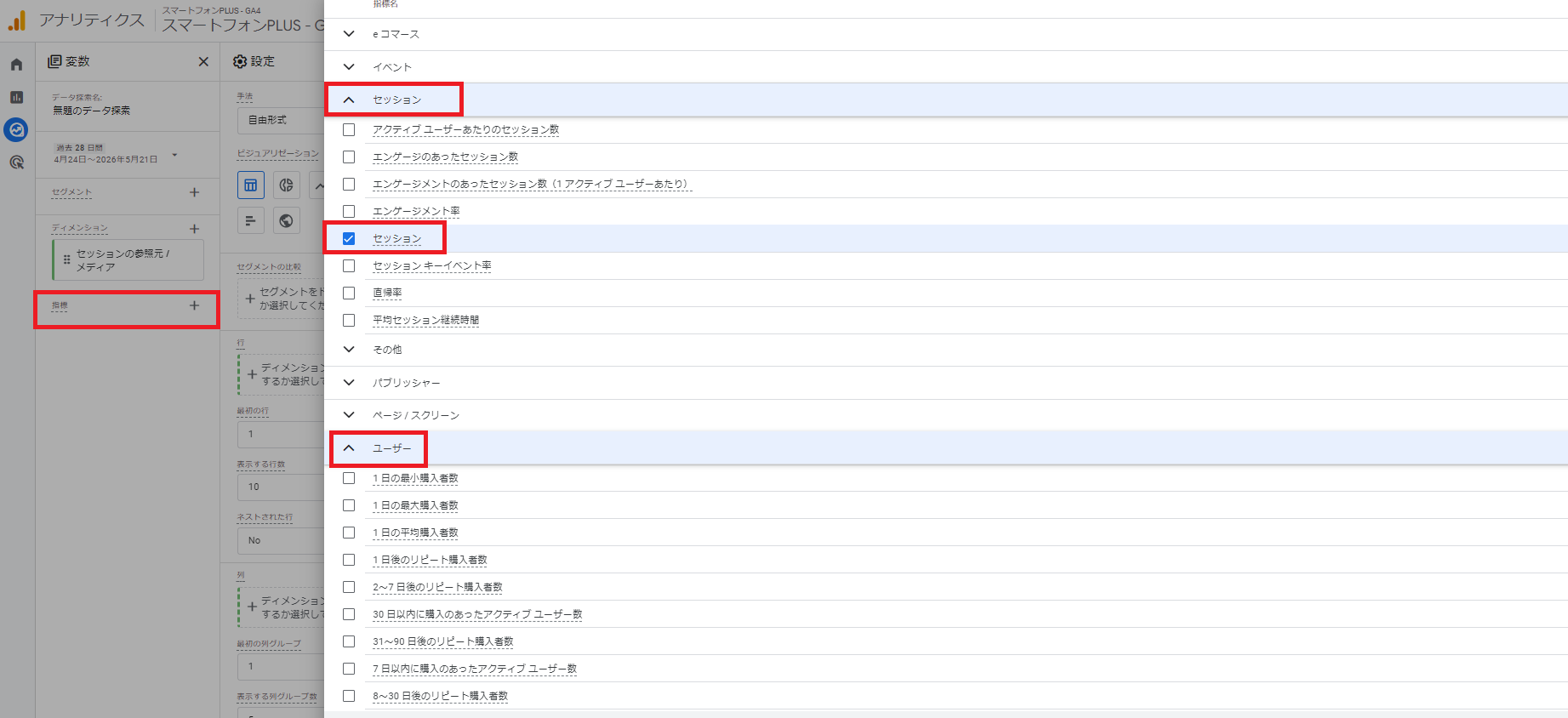
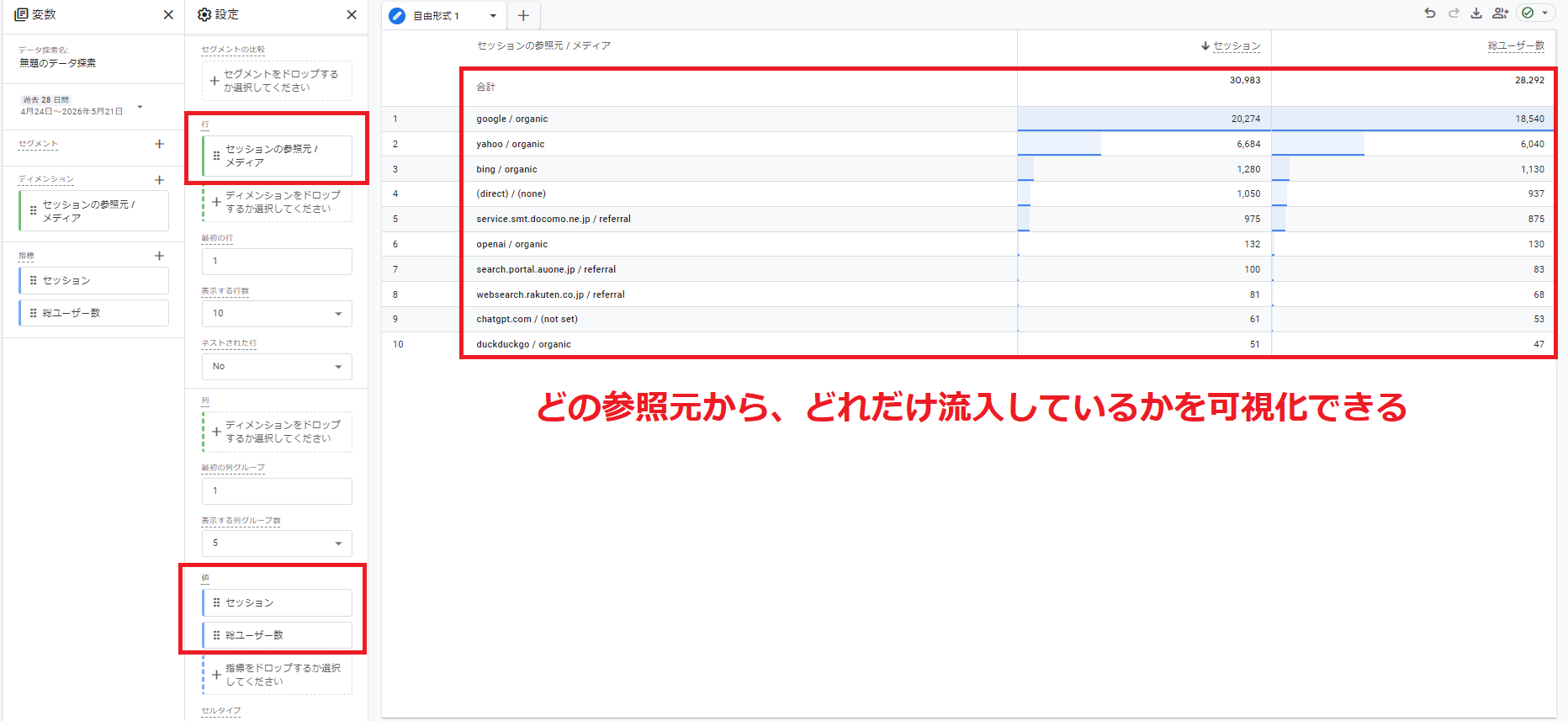
手順4. 設定の行に「セッションの参照元 / メディア」、値に「セッション」や「総ユーザー数」を追加する
手順5. フィルタに正規表現で「chatgpt.*|gemini.google.*|perplexity.*|copilot.*|claude.*」のように複数の生成AIを指定する
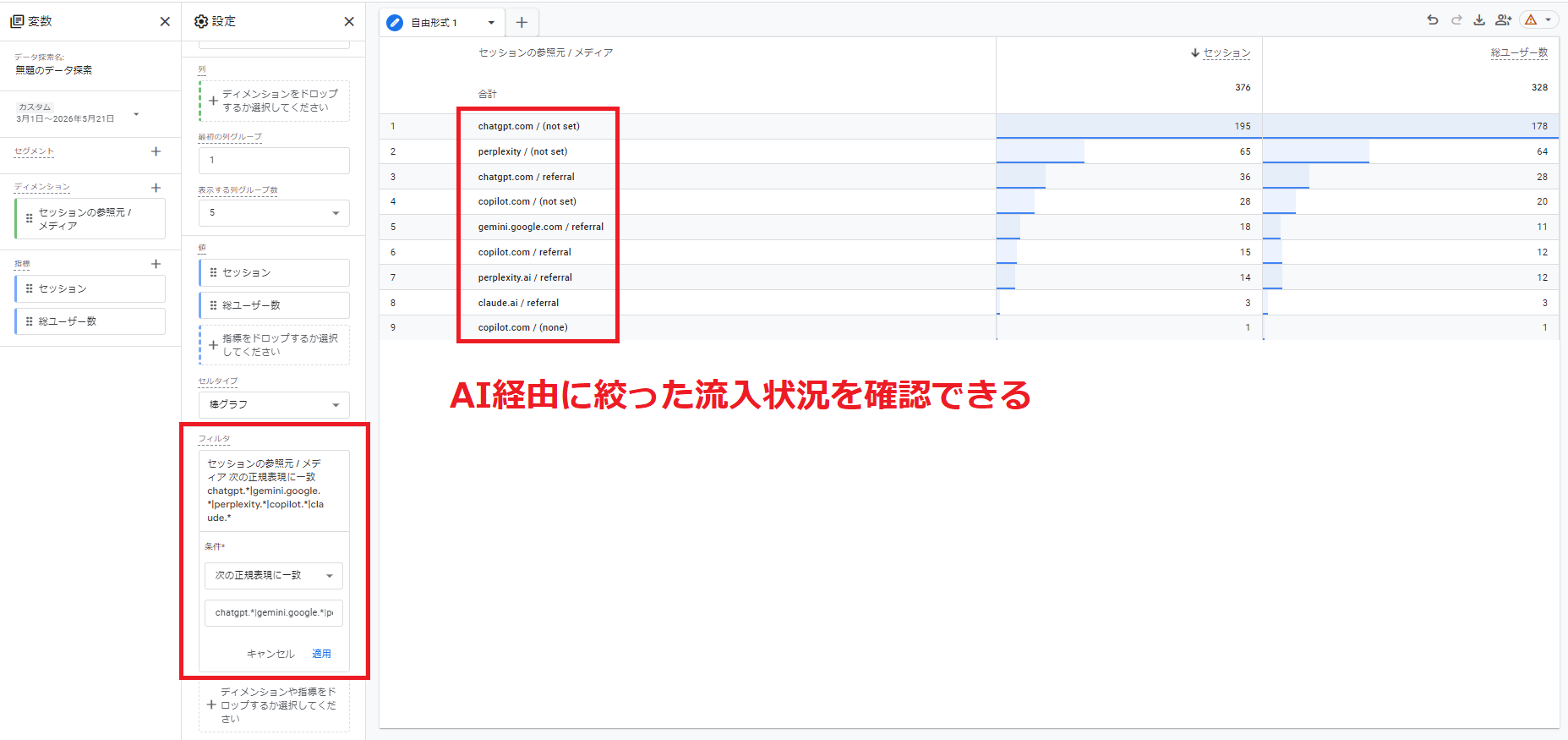
このフィルタを設定しておけば、AI経由の流入をまとめて把握できます。
「ランディングページ + クエリ文字列」をディメンションに追加すれば、どのページがAIからの流入を生んでいるかも特定可能です。
AIでの言及・引用の確認方法
AI Overviewsや各生成AIで、実際に自社が引用されているかを確認する方法もあります。
もっとも手軽なのは手動確認です。自社に関係するキーワードを10〜30個ほど選定し、Google検索やChatGPT、Geminiで実際に質問し、回答に自社サイトが引用元として表示されているか、ブランド名が言及されているかを記録していきます。
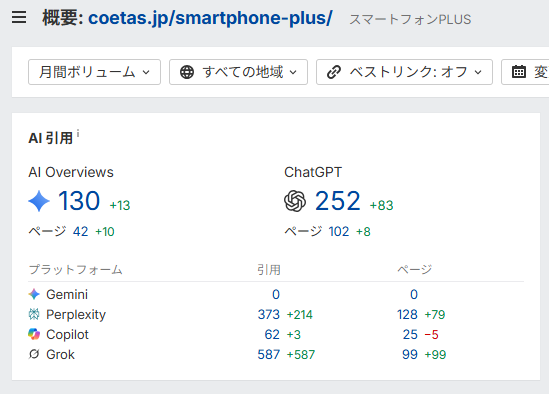
ツールを使いたい場合は、AhrefsのBrand Radar(ブランドレーダー)機能が有用です。
ブランド名やキーワードがAI Overviewsなどでどのように引用されているかを可視化する機能で、競合がどのキーワードで引用されているかも調査できます。
「自社が出ていないのに他社が出ているキーワード」を特定できれば、改修の優先順位を決めやすくなります。
海外ツールではProfound、Scrunch AI、Otterly.AIなどが生成AI上の引用状況を自動計測する機能を提供していますが、いずれも英語ベースで日本語対応が限定的なケースもあるため、まずは手動計測やAhrefsから始めるのが現実的でしょう。
評価すべき指標(順位ではない)
LLMO対策では、従来のSEOのように「検索順位」だけを見ていても効果を測りきれません。
1つ目は「AI経由の流入数」。GA4で測定できる、もっとも直接的な指標です。
2つ目は「指名検索数」。AIに自社名が登場すれば、その後で社名や商品名を入力して検索する人が増えます。Googleサーチコンソールで自社名関連キーワードの表示回数やクリック数の推移を追うと、認知拡大効果が見えてきます。
3つ目は「AI上での引用数」で、手動計測やAhrefs Brand Radarで把握できます。
4つ目は「AI経由のコンバージョン率(CVR)」。AI経由のユーザーは明確な情報ニーズや問い合わせ意図を持って訪問するケースが多いため、検索経由よりもCVRが高くなる傾向があります。3ヶ月〜半年というスパンで、複数指標を組み合わせて変化を見ていくのが基本姿勢です。
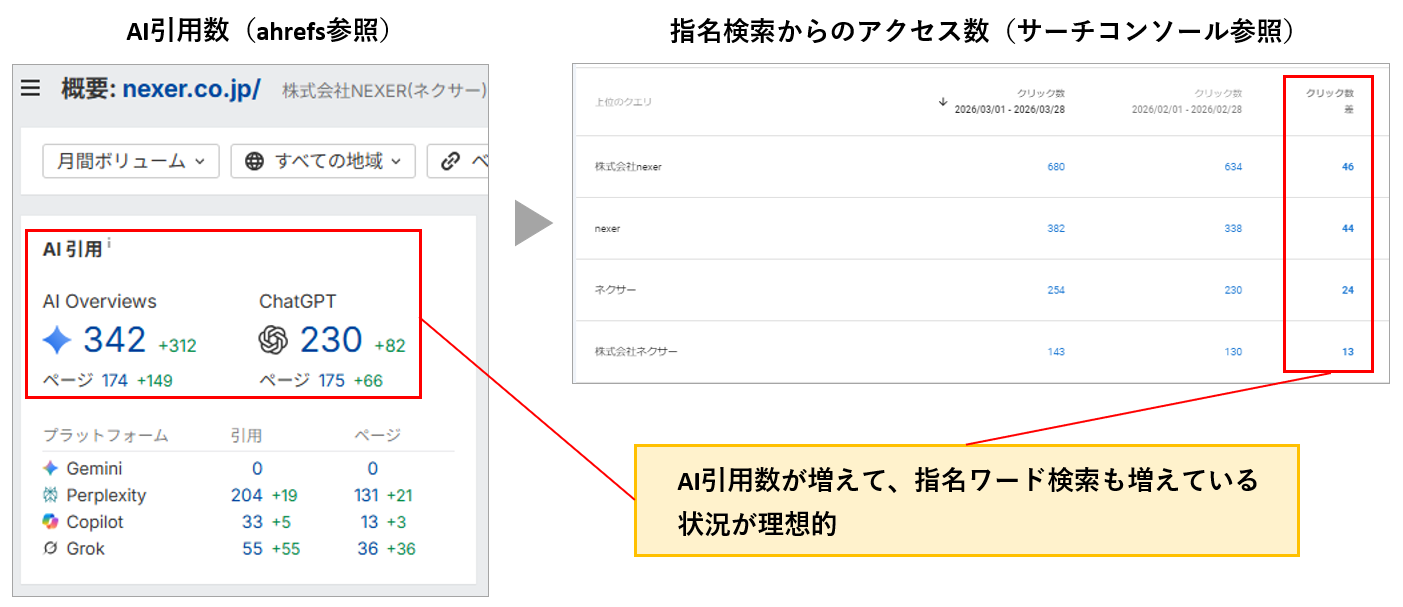
LLMO対策の実施例と成果が出ている企業の共通点
実際に企業がおこなっているLLMO対策の実施例やアンケート調査結果をもとに、現在主流となっている施策パターンや、成果が出やすい企業の共通点を解説します。
実施パターン(コンテンツ型・PR型など)
LLMO対策の取り組み方は、企業の業種・規模・目的によって大きく分かれます。
「コンテンツ型」はもっとも一般的で、自社オウンドメディアやブログで業界情報を網羅的に発信し、AIに引用される情報源としての地位を築きます。
「PR型」は外部メディアへの露出やプレスリリース、業界レポートの公開を通じて自社のサイテーションを増やすアプローチ。
「データ型」は、自社独自の調査データやレポートを継続的に公開してAIが引用したくなる「一次情報の発信元」になっていく戦略です。
「比較・レビュー型」は、ITreviewやBOXIL SaaSなどの比較プラットフォームでのレビュー獲得を重視するアプローチで、BtoB SaaS企業ではとくに重要になります。
【アンケート調査結果】他社がおこなっているLLMO対策
質問:AI検索対策(LLMOなど)で、取り組んでいる施策を教えてください(複数回答可)
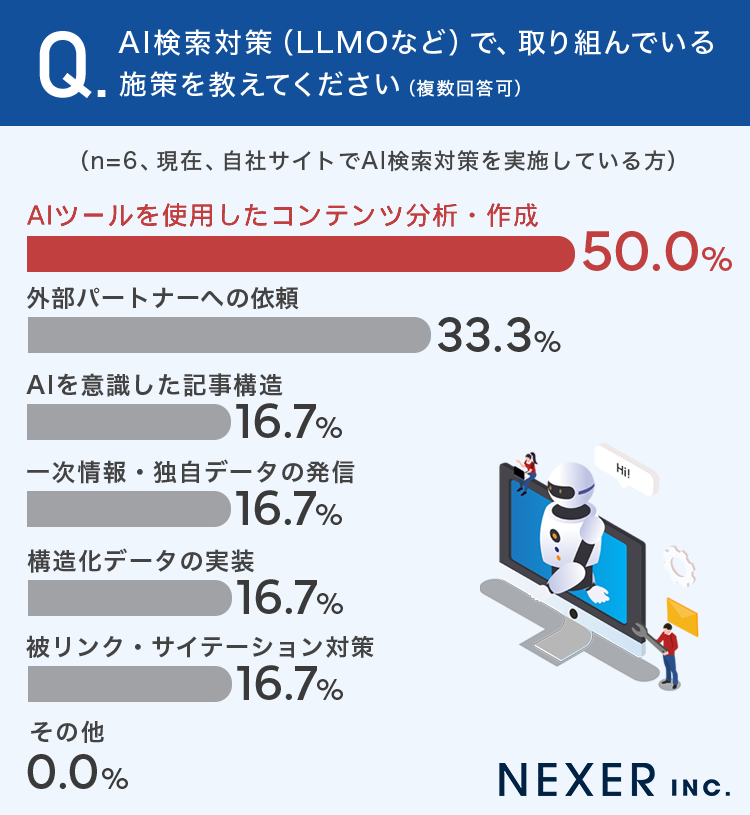
| AIを意識した記事構造 | 16.7% |
| 一次情報・独自データの発信 | 16.7% |
| 構造化データの実装 | 16.7% |
| 被リンク・サイテーション対策 | 16.7% |
| AIツールを使用したコンテンツ分析・作成 | 50.0% |
| 外部パートナーへの依頼 | 33.3% |
| その他 | 0.0% |
引用:【アンケート調査結果】AIが検索を変える時代、BtoBビジネス担当者のLLMOに関する意識・実態調査
現在、AI検索対策(LLMOなど)を実施している担当者に「どのような施策に取り組んでいるか」を聞いたところ、もっとも多かったのは「AIツールを使用したコンテンツ分析・作成」で50.0%でした。
ChatGPTやGeminiなどの生成AIを活用し、記事構成の改善や検索意図分析、コンテンツ作成の効率化を進める企業が増えていることがわかります。
一方で、「AIを意識した記事構造」「一次情報・独自データの発信」「構造化データの実装」「被リンク・サイテーション対策」はいずれも16.7%にとどまりました。
この結果から、現時点ではAIツールを使った制作効率化に取り組む企業は増えているものの、AIに引用されやすくするための本格的なLLMO施策まで実践できている企業はまだ少ないことがうかがえます。
また、「外部パートナーへの依頼」は33.3%となっており、専門知識や実装工数が必要な分野については、外部の支援を活用しながら進めている企業も一定数存在しているようです。
成果が出ている企業の共通点
LLMO対策で成果を出している企業を観察すると、いくつかの共通点が見えてきます。
1つ目は、SEOの基礎が整っていること。検索上位やドメイン評価の高いサイトはAI Overviewsの引用元としても選ばれやすいことが、複数の調査でも指摘されています。検索エンジンからの評価とAIからの評価は別物ではなく、地続きだということです。
2つ目は、独自の情報資産を持っていること。自社アンケートの集計結果、導入社数やCVRなどの実数値、現場での比較検証データといった「そのサイトにしか載っていない一次情報」を発信しているサイトは、AIから繰り返し引用される傾向があります。
3つ目は、トピックに対する網羅性。1つのテーマに関連する複数の疑問にまとめて答えられるサイト構造を持っていると、クエリファンアウトで生成された複数のサブクエリで引用される機会が広がります。
4つ目は、運営者情報や著者情報が明確に整理されているという点。「誰が、どんな経験や専門性をもとに書いているか」が明示されているサイトは、E-E-A-Tの観点からも信頼されやすくなります。
競合会社がLLMO対策をやっているか調べる
競合会社がLLMO対策をやっているのか調べるのにもっとも手軽なのが、実際にChatGPTやGoogleのAI Overviewsで業界関連のキーワードを検索してみる方法です。
たとえば自社が会計ソフトを提供しているなら、「中小企業向けの会計ソフトのおすすめを教えて」とAIに質問してみます。
回答の中に競合の名前が出ていれば、その競合はAIから認知されている状態にあります。
次に、競合サイトのコンテンツ構造を確認しましょう。
結論ファーストになっているか、FAQ形式が使われているか、独自データが掲載されているか。
これらは目視で確認しましょう。
NEXER Groupは、SEOで培った技術力を活かし、AI検索時代に対応したAIO/LLMO対策を提供しています。
無料分析で課題を可視化し、必要な施策のみを提案。20年以上・5,000社以上のSEO支援実績をもとに、AI Overviews対策や構造化データ実装などを一貫して支援いたします。
LLMO対策は自社でできる?外注すべき?

- LLMO対策は、SEOやコンテンツ制作の実務経験があれば、結論ファースト化やFAQ整備などの基本施策を自社でも内製可能
- 数百〜数千ページ規模の改善や、高度な構造化データ実装・戦略設計が必要な場合は、専門会社へ外注したほうが効率的。
- LLMO対策を内製するか外注するかは、「社内リソース」「緊急度」「予算」の3つを基準に判断することが重要
「LLMO対策はどこまで内製でできて、どこから外注すべきか」。リソースが限られている中小・中堅企業ほど、この判断に悩むはずです。
自社でできるケース
社内にSEOの実務経験者がいる場合、LLMO対策の基本部分は内製可能です。
結論ファースト化、FAQ形式の導入、運営者情報の整備などは、SEOで培ったスキルセットの延長で対応できます。
サイト規模が小さく、対策対象のページ数が10〜30ページ程度であれば、優先度の高いページから順に手を入れていけば3ヶ月程度で一巡できます。
特定の専門分野に強みがあり、独自情報を自前で発信できる場合は、社内の専門家が直接執筆や監修にかかわるほうが、E-E-A-Tの観点でも好影響です。
外注すべきケース
社内にSEOやWebマーケティングの専任者がいない、もしくは担当者が兼務で時間が取れない場合は、外注を検討するのが現実的です。
サイト規模が大きく、数百〜数千ページの対策が必要な場合も、優先度づけや一括改修の型を持っている専門会社に任せたほうが、自社で一から手探りするより着手から成果までの期間を短縮できます。
JavaScriptの修正による、サイトのパフォーマンス改善まで踏み込む必要がある場合も、エンジニアリングの工数を社内で確保するのが難しければ外注のほうがトータルコストを抑えられます。
競合が先行してAI検索に最適化を進めており自社が劣勢に立たされている場合はスピードが命。
外部の専門家に伴走してもらい、半年〜1年で一気に追いつくほうが結果として効率的でしょう。
判断基準(リソース・目的別)
外注するかどうかの判断は、次の3軸で考えるとシンプルです。
1つ目は「社内リソース」。担当者の時間とスキルセットに余裕があれば内製、不足していれば外注が基本線です。
2つ目は「目的の緊急度」。急ぎなら外注で時間を買うほうが合理的で、中長期で資産化したいなら内製でじっくり進める選択肢もあります。
3つ目は「予算規模」。月数十万円〜数百万円というLLMO対策の費用感と、社内採用の人件費を比較してください。
「戦略設計と全体方針は外注、現場の更新作業は内製」のようなハイブリッド体制も、多くの企業で採用されています。
以下に外注すべきかどうかの診断シートを用意いたしました。こちらの結果を基に検討してみてください。
| 診断項目 | YESの場合 | NOの場合 |
|---|---|---|
| 社内にSEO・Webマーケティングの実務経験者がいる | 内製向き | 外注を検討 |
| 担当者がLLMO対策に十分な時間を確保できる | 内製向き | 外注を検討 |
| 短期間で成果を出したい | 外注向き | 内製でも可 |
| 中長期で社内ノウハウを蓄積したい | 内製向き | 外注でも可 |
| 数百〜数千ページ規模の対策が必要 | 外注向き | 内製でも対応可能 |
| JavaScriptなどの技術改善を社内で対応できる | 内製向き | 外注向き |
| 月数十万円以上の予算を確保できる | 外注しやすい | 内製中心がおすすめ |
NEXER Groupは、SEOで培った技術力を活かし、AI検索時代に対応したAIO/LLMO対策を提供しています。
無料分析で課題を可視化し、必要な施策のみを提案。20年以上・5,000社以上のSEO支援実績をもとに、AI Overviews対策や構造化データ実装などを一貫して支援いたします。
LLMO対策のNG施策・よくある失敗

- LLMO対策では、キーワードを不自然に詰め込む施策は逆効果。生成AIはキーワード数ではなく、文章の意味や情報構造を重視して評価する。
- 生成AIに認識・引用されるまでには時間がかかるため、LLMO対策は短期成果ではなく、中長期で継続的に改善していくことが重要。
- llms.txtの設置や未検証ツールへの過度な投資よりも、E-E-A-T強化・一次情報の追加など基本施策を優先するべき。
LLMO対策で特に多い失敗パターンや、効果が出にくいNG施策をまとめておきます。
SEOの延長で考えすぎる失敗
LLMO対策をSEOの完全な延長として捉えてしまうと、いくつかの落とし穴にはまります。
キーワードの出現頻度を機械的に増やす「キーワード詰め込み」はその代表例。
SEOでも効果が薄い手法ですが、LLMO対策では完全に逆効果です。
AIはキーワードの密度ではなく、文章の意味や構造で情報を評価するため、不自然な反復はむしろ品質を下げる要因になります。
被リンクを大量に集める従来型のリンクビルディングだけに頼るのも危険。
LLMO対策では、リンクの本数よりも「どんな媒体で、誰に、どんな文脈で言及されているか」という言及の中身が重視されます。
また、検索順位だけを評価指標にするのも失敗のもとです。
検索順位は高いままでもAI Overviewsでクリック率が下がる現象は実際に起きており、AI経由の流入や引用回数といった指標も組み合わせて見ていく必要があります。
施策が分散して成果が出ない失敗
「あれもこれも」と手を出しすぎて、結局どれも中途半端になるパターンもよく見られます。
LLMO対策にはコンテンツ・E-E-A-T・技術・外部対策と4領域あり、それぞれにさらに細かい施策があります。
優先順位を明確にし、まずは「もっとも費用対効果が高い1〜2の施策」に集中するのが鉄則。
先述のチェックリストで現状の弱点を把握し、もっとも改善余地が大きい部分から手をつけていきましょう。
効果が出るまでに時間がかかる施策と短期で効く施策を組み合わせるのもポイントです。
「結論ファースト化」は短期で効くため、まず着手して感触を掴みつつ、独自データの蓄積は中長期で取り組む、という分け方が現実的です。
短期成果を求めすぎる失敗
LLMO対策で多い誤解が「数週間で目に見える成果が出る」という期待感です。
生成AIは事前学習データとリアルタイムの検索情報を組み合わせて回答を生成しているため、新しいコンテンツがAIに認識・引用されるまでには、ある程度の時間が必要です。
3〜6ヶ月、場合によってはそれ以上のスパンで継続的に取り組むことが前提になります。
AIアルゴリズム自体も日々変化しており、「これをやれば必ず効果が出る」という確実な施策が確立されているわけではありません。
基本原則を踏まえつつ、定期的に効果を測定し、軌道修正しながら進めるという、地道なPDCAが求められます。
効果の薄い施策に時間を使ってしまう失敗
最後に、現時点では効果が薄いとされる施策に過剰な時間を投入してしまう失敗にも注意が必要です。
代表例が、前述したllms.txtの設置。将来的に普及する可能性は否定できませんが、現時点で大きな手間をかけて整備する優先度は決して高くありません。
AIへのフィードバック送信も、それ自体は無料で誰でもできますが、これだけで状況が大きく変わるわけではなく、補助的に取り組む位置づけが妥当です。
未検証の海外ツールへの本格投資も慎重に判断すべきです。多くは英語ベースで日本語環境での精度は限定的。
まず手動計測で肌感覚を掴み、必要性を見極めてから導入を判断しましょう。
具体的な失敗というところでいうと「コラムだけを施策として運用した時」でしょうか。
競合性の高い業界だったこともあり、各AIの引用数を思うように伸ばすことができませんでした。
SEOと似たような話になりますが、外部からの強化によるサイトの権威性や信頼性の重要性を再認識することとなりました。
まとめ
ここまで、LLMO対策の定義から具体的な施策、優先順位、効果測定、外注判断、よくある失敗まで一通り解説してきました。
LLMO対策とは、ChatGPTやGoogleのAI Overviewsなど生成AIに、自社を有益な情報参照元として認識・引用してもらえるようWebサイトを最適化する施策のこと。SEOの延長線上にあり、土台のSEOが整っているほど効果も出やすくなります。
AIの回答生成にはクエリファンアウトという技術が使われており、1つの質問が複数のサブクエリに分解されるため、テーマに対する網羅的なコンテンツ設計が鍵になります。
具体的な対策は「コンテンツ設計(結論ファースト・FAQ)」「E-E-A-Tの強化」「技術的最適化」「サイテーション獲得などの外部対策」の4領域。まずは既存コンテンツの結論ファースト化やFAQの設置から始めるのが良いでしょう。
とはいえ、社内のリソースだけでLLMO対策を一通り回していくのは、多くの企業にとってハードルが高い現実があります。「何から手をつければいいか整理しきれない」「効果測定の仕組みまで作る余裕がない」「競合に先行されていて早急に巻き返したい」。そうした状況であれば、専門家に伴走してもらうことも有力な選択肢になります。
本記事を参考に、競合会社よりも一歩先にLLMO対策を初めてみてはいかがでしょうか?
