AIO・SEO
AIO・SEOブログ
マルチモーダルAIとは?仕組みで分かるAI検索の「脱・テキスト」SEO戦略
2026.03.03 SEO
この記事の監修SEO会社
株式会社NEXER
2005年にSEO事業を開始し、計5,000社以上にSEOコンサルティング実績を持つSEOの専門会社。
自社でSEO研究チームを持ち、「クライアントのサイト分析」「コンテンツ対策」「外部対策」「内部対策」「クライアントサポート」全て自社のみで提供可能なフルオーダーSEOを提供している。
SEOのノウハウを活かして、年間数百万PVの自社メディアを複数運営。
「キーワード選定と文章さえしっかり書けば上位表示される」
そんなSEOの常識は、過去のものになろうとしています。
現在、AI検索市場はGoogleのGeminiに代表される「マルチモーダルAI」によって、大きな進化を遂げています。
これによって、AIはテキスト情報だけでなく、画像、音声、動画から情報を理解することが可能になりました。
つまり、テキストだけで最適化されたSEO記事は、AIにとっては情報不足と認識されるリスクが生じるのです。
この記事では、マルチモーダルAIの仕組みから、それによって検索体験がどう変わったのかを解説します。
また、SEO記事をマルチモーダルAIに対応する具体策から、実践で使えるAIツールまで紹介します。

SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
目次
マルチモーダルAIとは
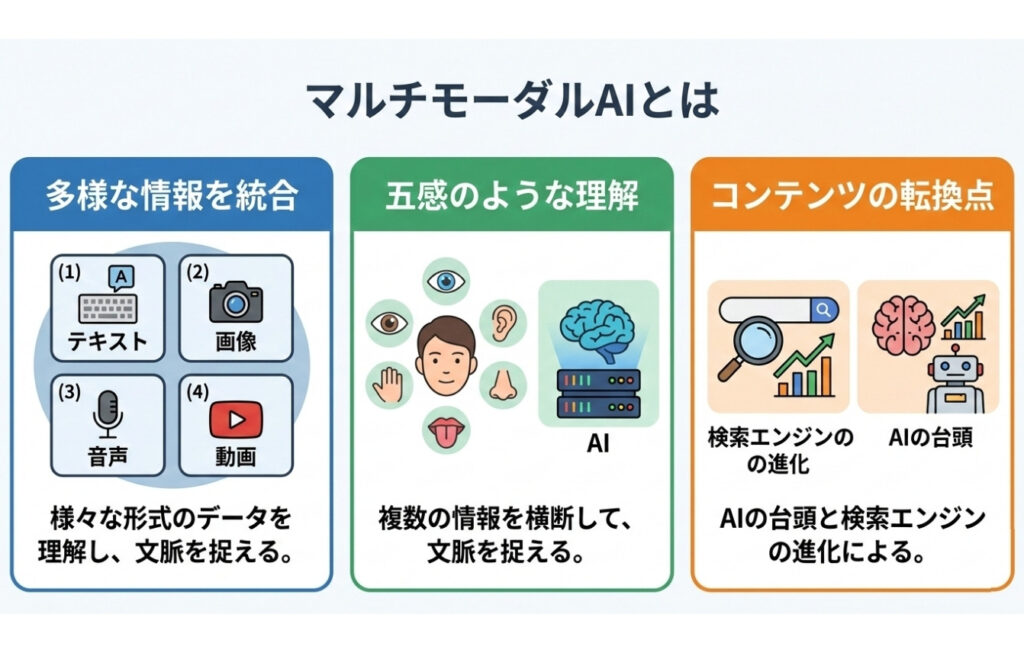
マルチモーダルAIは、テキストだけでなく画像や音声、動画といった多様な情報を統合して処理する次世代のAI技術です。
人間が五感を通じて情報を理解するように、AIも複数の様式の情報を横断して文脈を捉えることが可能になりました。
検索エンジンの進化やAIの台頭により、コンテンツの在り方は今まさに大きな転換点を迎えています。
まずは「マルチモーダルAI」の定義を整理し、従来技術との違いや身近な活用事例を解説します。
マルチモーダルAIと生成AI(シングルーモダル)の違い
マルチモーダルAIと従来の生成AI(シングルモーダル)の決定的な違いは、扱える情報の種類とそれらを統合する能力にあります。
従来のシングルモーダルはテキストなどの単一データに限定されていましたが、マルチモーダルAIは画像や音声、動画といった複数の「モダリティ」を同時に解析し、相互に関連付けて理解することが可能です。
| 生成AI(シングルモーダル) | マルチモーダルAI | |
|---|---|---|
| 入力情報 | 主にテキスト | テキスト、画像、音声、動画など |
| 理解の仕組み | 言語的な関連性のみ | 視覚・聴覚を含む多角的な照合 |
| 出力形式 | 主にテキスト | 状況に応じた多様な形式 |
シングルモーダルが「特定の感覚」だけで情報を追う状態なら、マルチモーダルAIは「五感」を駆使して世界を捉える状態と言えます。
これにより、テキストの裏にある文脈や視覚情報の意味までAIが正確に把握できるようになりました。
現代のSEOにおいては、単なるキーワード対策に留まらず、テキスト以外の非構造化データをいかに最適化するかが重要になります。
マルチモーダルAIが日常で使われている事例
マルチモーダルAIは、複数の情報を組み合わせることで、単一のデータ処理では不可能だった「複雑な状況判断」を可能にし、私たちの生活を支えています。
代表的な活用事例は以下の通りです。
- 自動運転システム
カメラの映像、レーダーの距離情報、音声による緊急車両の検知などを瞬時に統合し、安全な走行を制御します。 - 医療診断支援
レントゲンや画像データと、患者の症状を記したテキストデータを組み合わせて多角的な分析を行います。 - 高機能スマートスピーカー
音声命令だけでなく、内蔵カメラでユーザーのジェスチャーや表情を読み取り、文脈に応じた最適な応答を返します。
これらの技術に共通しているのは、ユーザーがわざわざ言語化してテキストを打ち込む手間を省いている点です。
SEO戦略においても、こうした「検索の非言語化」が進んでいる背景を理解し、多覚的なデータ形式に対応する視点が不可欠となっています。
マルチモーダルAIの仕組み
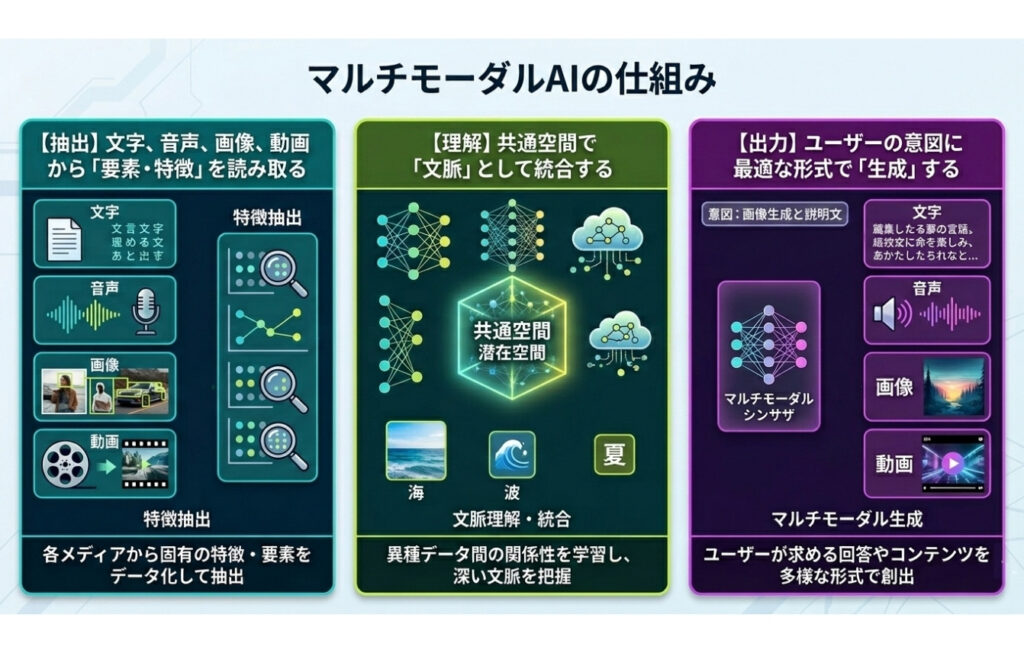
マルチモーダルAIが多様な情報を処理する仕組みは、主に3つのプロセスで構成されています。
各プロセスが高度に連携することで、人間が「目や耳」で状況を判断するような直感的な情報処理が実現します。
マルチモーダルAIを活用したAI検索に最適化するには、まずこの仕組みを理解することが必要です。
- 【抽出】文字、音声、画像、動画から「要素・特徴」を読み取る
- 【理解】共通空間で「文脈」として統合する
- 【出力】ユーザーの意図に最適な形式で「生成」する
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
【抽出】文字、音声、画像、動画から「要素・特徴」を読み取る
「抽出」は、マルチモーダルAIがWebサイト上のあらゆるデータを理解可能な形式へ変換する、情報処理の土台となるステップです。
画像であれば色や輪郭、音声であれば波形やトーン、動画であれば動きの変化といった各要素を「特徴量」として抜き出します。
AIはこれらを人間のように直接見聞きするのではなく、共通の「数値データ」に置き換えることで、情報の断片を解析可能な状態へと落とし込んでいきます。
これにより、従来のSEOにおける情報の捉え方は、以下のようにアップデートされました。
- 画像はalt属性だけでなく、画像そのものに映る視覚情報も重要になった。
- 画像や動画が一次情報としての価値を証明するデータになった。
「抽出」の精度が向上したことで、AIはテキスト以外のデータからも深い意味を汲み取れるようになりました。
AIが解析しやすい高品質な素材を提供することが、次世代のAI検索の最適化における課題となります。
【理解】共通空間で「文脈」として統合する
「理解」のプロセスは、抽出された個々のデータを一つの大きな「文脈」として繋ぎ合わせる段階です。
テキスト、画像、音声といったバラバラの形式の情報を、AI内部の「共通空間」に配置し直します。
これにより、AIは「リンゴ」という文字と「赤い果実の画像」が同じ概念であることを認識し、情報同士の相関関係を深く理解することが可能になります。
このプロセスにおいて、従来のSEOの考え方が以下のように変わりました。
- 画像とテキストの内容に一貫性がないと、情報の信頼性が損なわれるリスクとなった。
- テキストを補完する図解があることで、専門性を補完できるようになった。
ユーザーの検索意図に対して、テキストとビジュアルが同期したコンテンツを提供することが、AI検索時代において重要になります。
【出力】ユーザーの意図に最適な形式で「生成」する
「出力」のプロセスは、AIが理解した情報をユーザーの状況やデバイスに合わせて、最も価値のある形で「再構成」する最終段階です。
単に情報を提示するだけでなく、質問者が何を求めているかという意図を汲み取り、テキスト、画像、あるいは音声といった最適な「モダリティ」を選択して回答を生成します。
これにより、ユーザーは膨大な検索結果を読み解く手間から解放され、瞬時に解決策を得ることが可能になります。
AIの「出力」が高度化した結果、我々が取り組むべきSEOの焦点は、以下のようにシフトしています。
- 満足度の高い要約回答が提示されることで、記事をクリックする人が減った。
- AIが理解しやすい「構造化された情報」の配置が、AIの回答根拠に選ばれやすくなった。
「出力」の質が高まったことで、AIはユーザーに「候補を提示する」のではなく「答えを教える」存在へと進化しました。
マルチモーダルAIを活用した代表的な生成AIモデル

マルチモーダルAIは急速に進化しており、各社から高性能なモデルが次々と登場しています。
画像認識や音声処理に独自の強みを持つこれらのモデルは、私たちの検索体験を劇的に変えつつあります。
AI検索の時代に無視できない主要な3モデルの「マルチモーダル機能」の特徴について解説します。
| Gemini | Google検索と深く連携する生成AIモデル |
|---|---|
| ChatGPT | 高度な推論と対話力を備えた生成AIモデル |
| Grok | Xのリアルタイムデータを活用する生成AIモデル |
Gemini
「Gemini」は、Googleが開発した次世代のマルチモーダルAIであり、AI検索の未来を担う中心的な存在です。
大きな特徴は、従来のGoogle検索の中に組み込まれている点です。
参照:Google Japan Blog「Gemini 3 を搭載した Google 検索」
これにより、従来の検索ユーザーに与える影響力も大きく、SEOにおいても無視できないAIモデルと言えます。
- 長いPDFの内容を理解・要約
- 動画の内容理解や要約
- テキストから画像・動画生成
- テキストからコード生成
- 音声会話での対話
- カメラを使ってリアルタイムに映したものを解説
参照:Google for developers「Gemini のマルチモーダル機能の 7 つの実例」
- Google Workspace(GmailやGoogleドキュメントなど)との連携により、ビジネスシーンでの利用が急速に拡大。
- Google検索の基盤を担っており、YouTube動画のAI引用率を高めている。
ahrefsの2025年の調査では、YouTubeが「AI Overviews」と「AIモード」の両方で、引用数がもっとも多いドメインとして記録されています。
参照:ahrefs「【AI による概要 vs AI モード】日本におけるトップ 1000 引用ドメイン分析から見えてきた相関性とは?」
Google検索の「AI化」への最適化と、動画コンテンツの制作が、これからのSEO・AIO戦略において最優先の課題となります。
ChatGPT
「ChatGPT」は、OpenAIが開発した世界で最も普及している生成AIのパイオニア的存在です。
Geminiと同様に、テキスト・画像・音声といった多様な形式のデータをシームレスに処理できる標準的な「マルチモーダル機能」を網羅しています。
人間のように画像や音声を理解し、対話できるようになったことで、ビジネスからプライベートまで幅広いシーンで「検索の代替手段」として定着しています。
- 動画の内容理解や要約
- テキストから画像・動画生成
- テキストからコード生成
- 音声会話での対話
- カメラを使ってリアルタイムに映したものを解説
- 2025年12月時点、最も普及率の高い生成AIモデル。
- 今後普及率が上がれば「ググる」から「AIに聞く」がスタンダードになる可能性。
Ragate株式会社のビジネスパーソン505名を対象にした調査では、「ChatGPT」が45.5%と、最も高い普及率であることが分かりました。
参照:Ragate株式会社「【2025年最新調査】企業における生成AI導入状況レポート」
「ChatGPT」のトップシェアが今後も続くかどうかで、AI最適化の対象も変わるため、今後もシェア動向に注目しなければいけません。
Grok

「Grok」は、イーロン・マスク氏率いるxAI社が開発したマルチモーダルAIであり、SNSプラットフォーム「X」と完全に一体化している点が特徴です。
これにより、特別なツールを立ち上げることなく、タイムラインを眺める感覚でAIを自然に活用するユーザーが増えています。
GeminiやChatGPTと同様に、テキストだけでなく画像や動画の内容を即座に理解し、X上の膨大なリアルタイム情報と組み合わせて回答を生成することに長けています。
- タイムラインに流れる画像や動画の解説
- テキストからSNS投稿用の画像・動画生成
- 投稿された情報の真偽や背景を補足(ファクトチェック支援)
- マルチモーダルAIの日常化
- これまでAIに触れていなかった潜在層への活性化
Grokのような「SNS一体型AI」の普及は、ユーザーが画像や動画を使って「これは何?」と日常的に検索する文化を加速させています。
人間の情報収集やリサーチ手段の概念を大きく変える意味でも、SEOへの影響力は高いと考えられます。
マルチモーダルAIによって変わるユーザーの検索体験

マルチモーダルAIの普及によって、ユーザーの検索行動は「テキストへの変換」という手間から解放されます。
五感をそのままデジタルに接続するような、より直感的でストレスのない検索体験へと進化しています。
本項では、マルチモーダルAIがもたらす検索体験の劇的な変化を、以下の3つのポイントで解説します。
- 会話形式で質問できる自然な音声検索
- 言葉にできないものを探せる高度な画像検索
- カメラを使った現実世界のリアルタイム検索
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
会話形式で質問できる自然な音声検索
最新のAIは音声認識の精度も向上したため、「あー」「えーっと」のような言葉が混ざっても正確に意図を読み取ることができます。
音声検索は、画面を注視したりキーボードを叩いたりする手間が省けるのも大きな魅力です。
まるで、いつでもどこでも専門家をすぐに呼び出して、教えてもらうような検索方法が定着しています。
- 料理をしながらレシピを調べる
- 運動をしながら調べものをする
- 布団の中で寝ながら調べものをする
言葉にできないものを探せる高度な画像検索
「名前は分からないけれど、これについて知りたい」という、言語化できないもどかしさを解消するのが高度な画像検索です。
マルチモーダルAIが、画像内の色、形状、質感などを瞬時に解析するため、ユーザーは特徴を言葉で説明して検索し直す手間がありません。
まるで子供が気になったものに「これ何?」と、指をさして聞くような検索体験が広がっています。
- 街で見かけた花や植物の名前を調べる
- SNSで見かけた服や小物がどこで売っているか探す
- 旅先で見つけた歴史的な建物の名前や背景を調べる
カメラを使った現実世界のリアルタイム検索
スマホのカメラを「レンズ」として現実世界にかざすだけで、映像をその場で解析するのがリアルタイム検索です。
静止画をアップロードする手間さえなく、目の前の風景や物体をAIに見せることで、今その瞬間の状況を検索できるようになりました。
現実世界のすべてが検索対象となったようなシームレスな感覚は、ユーザーの検索体験に革命をもたらしたと言えます。
- 外国語のメニューや看板を見せ、その場で翻訳する
- 機械の不具合の状態を見せ、故障の原因を調べる
- 店舗で複数の商品を見せ、性能を比較する
従来のSEOだけでは通用しなくなる理由

従来のSEOは「テキスト」と「キーワード」を主軸に構築されてきましたが、マルチモーダルAIの台頭によってその前提が大きく崩れつつあります。
AIが画像や動画を直接理解し、ユーザーに代わって情報を集約するようになった今、これまでの対策だけではWebサイトの露出を維持することが困難です。
従来のSEOだけでは通用しなくなる決定的な理由を、4つの視点で解説します。
| 検索行動の変化 | AI検索へのシフト |
|---|---|
| 評価対象の変化 | マルチモーダルによる多角照合 |
| トラフィックの変化 | ゼロクリック検索の一般化 |
| 競合の変化 | AI引用率が高いYouTubeの台頭 |
検索行動の変化:AI検索へのシフト
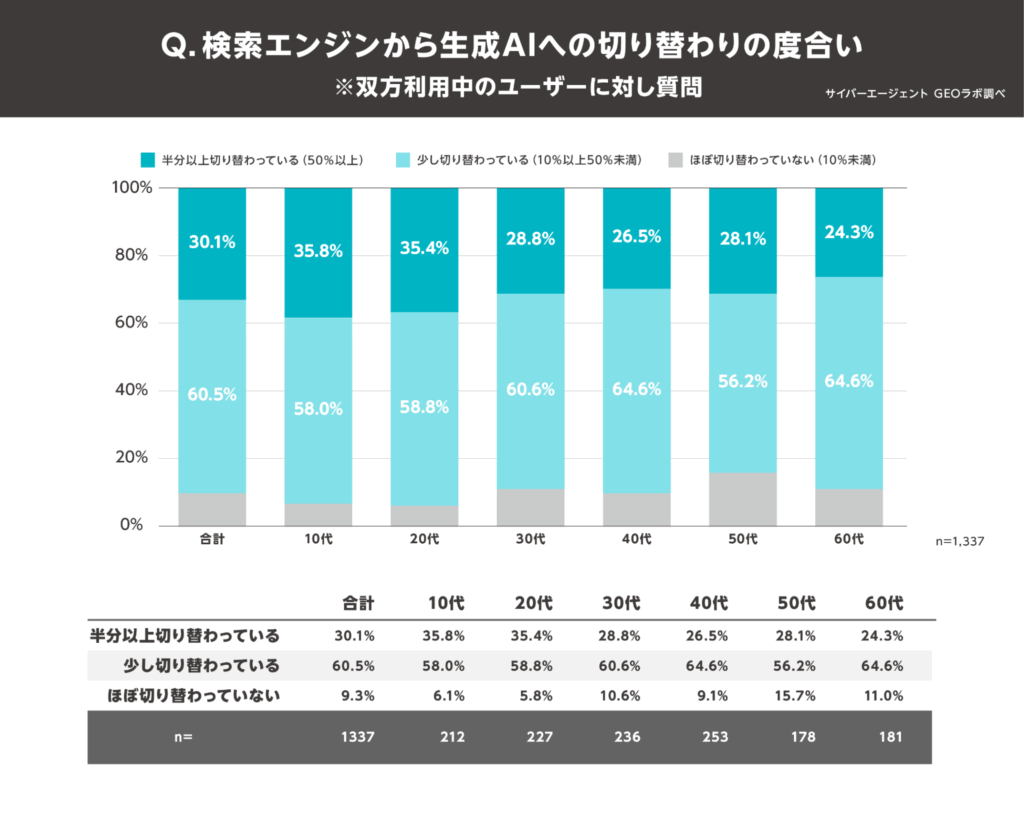
参照:サイバーエージェント GEOラボ「生成AIのユーザー利用実態調査を実施」
これは、2025年に行われた株式会社サイバーエージェントの全国10代~60代の男女9,278名を対象にした調査です。
検索エンジンと生成AIの両方を使うユーザーに対する質問で、「検索エンジンから生成AIに半分以上切り替わっている」と回答した人が、全体で30.1%もいることが分かりました。
この数値は、もはや「AI検索は一部のリテラシー層だけのもの」ではないことを明確に示しています。
若年層を中心に、情報を探す際の「第一選択肢」として、検索エンジンからAIへと移り変わりつつあるのです。
AIはユーザーの曖昧な意図を先回りして解決するため、従来の「キーワードで検索結果のリストを出しサイトを吟味する」というプロセスそのものが、省略されるようになりました。
この検索行動の根本的な変化が、従来のSEOだけでは通用しなくなる最大の要因です。
評価対象の変化:マルチモーダルによる多角照合
従来のSEOでは、検索ボリュームの大きなキーワードを抽出し、それらを本文中に適切に配置する「キーワード主導型」の設計が王道でした。
しかし、マルチモーダルAIの台頭により、AIはテキスト・画像・動画をバラバラではなく「一つの文脈」として同時に解析(多角照合)するようになっています。
これにより、単にキーワードを網羅するだけでは不十分で、「独自の体験(一次情報)」が含まれているかというテキスト以外の情報も大きな評価対象になります。
従来のGoogle検索と、現在のマルチモーダルAI検索の違いを整理すると、以下の通りです。
| 従来のGoogle検索(SEO) | マルチモーダルAI検索 | |
|---|---|---|
| 設計の起点 | キーワード選定 | 検索意図を満たす構造設計 |
| 評価軸 | キーワード最適化 | AIに分かりやすい文章構造・E-E-A-T要素や一次情報の密度 |
| 画像・動画の役割 | テキストの補足や装飾(主にalt属性で内容を伝える) | 独立した有力な情報源(AIが画像・映像を直接解析) |
SEOの記事制作においても、従来の考え方ではAI検索に評価されないことが分かります。
トラフィックの変化:ゼロクリック検索の一般化
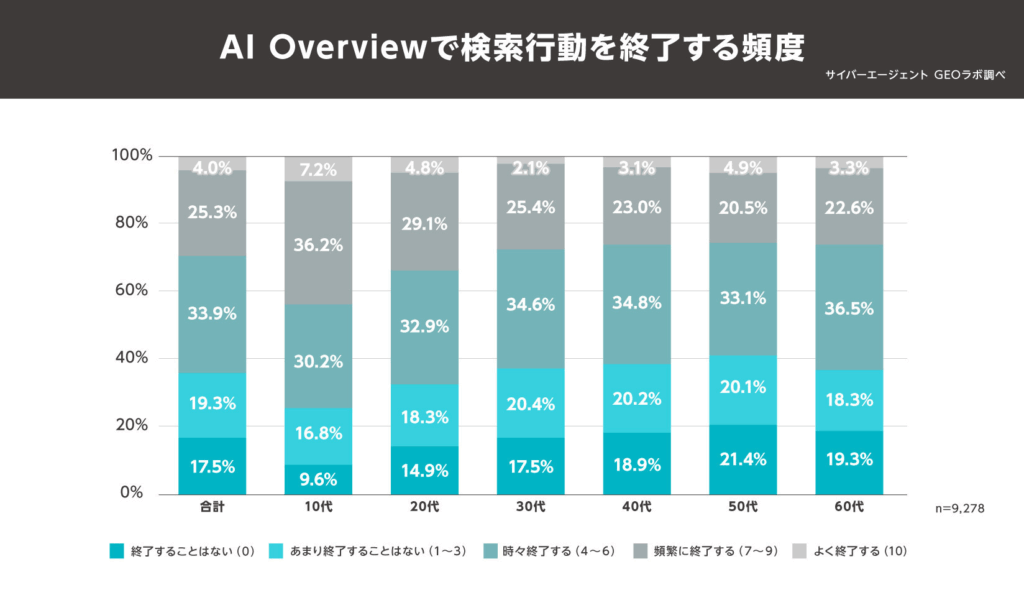
参照:サイバーエージェント GEOラボ「AI Overviewの利用率に関するユーザー調査を実施」
こちらも、2025年に行われた株式会社サイバーエージェントの調査です。
Google検索の結果に表示される「AI Overviews」だけで検索行動を、「時々終了する」「頻繁に終了する」「よく終了する」と回答した人の割合が、全体の合計で63.2%もいることが分かりました。
このデータは、これまでのSEOの常識を根底から覆す「ゼロクリック検索」を意味しています。
従来、検索順位で1位を獲得することの最大の目的は、ユーザーを自社サイトへ「クリック」させることでした。
しかし、今やユーザーの6割以上が、個別のWebサイトを訪問することなく、検索結果画面(SERP)上のAI要約を読むだけで検索行動を終えています。
競合の変化:AI引用率が高いYouTubeの台頭
マルチモーダルAI時代において、SEOの競合相手はもはや他社のWebサイトだけではありません。
2025年のahrefsの調査で、Googleの「AI Overviews」「AIモード」において、もっとも引用されているドメインは「YouTube」です。
参照:参考:ahrefs「【AI による概要 vs AI モード】日本におけるトップ 1000 引用ドメイン分析から見えてきた相関性とは?」
このようにAIは、テキスト情報よりも動画内の解説や実演を、ユーザーにとって最も「質の高い回答」であると判断する傾向が強まっています。
SEO現場で求められる6つのマルチモーダルAI対策

AI検索が、コンテンツの「信頼性の証拠」としてビジュアル情報を直接解析するようになった今、テキストだけに頼った従来のSEOは限界を迎えています。
これからのSEO現場では、AIに情報を「読ませる」だけでなく、画像や動画を通じて「理解・照合させる」戦略的なアプローチが不可欠です。
マルチモーダルAI時代に勝ち残るために、SEO現場で取り組むべき具体的な6つの対策を紹介します。
- 脱・テキストオンリー記事
- 抽象的なアイキャッチを図解に変換
- 画像の高画質&軽量化
- YouTube展開と記事との連携
- alt属性の再定義
- 複数のモダリティ内での整合性を保つ
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
①脱・テキストオンリー記事
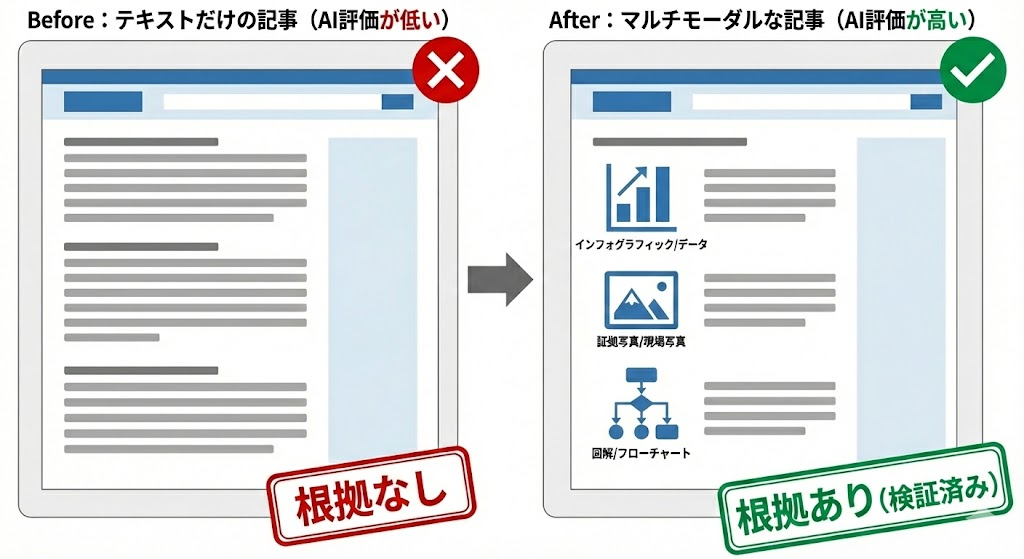
マルチモーダルAI時代において、文字だけで構成された記事は、土俵にすら立てなくなってきているのが現実です。
AIが画像や動画を「情報の根拠」として直接解析する以上、テキストのみのコンテンツはそれだけで評価対象から外れるリスクがあります。
もはや「装飾としての画像」ではなく、テキストの内容を視覚的に証明する「エビデンス(証拠)」の配置は、執筆における最低限のマナーになっています。
- 見出し(H2)ごとに内容を補完する視覚情報を必ず配置
- 記事の結論を一枚で理解できるインフォグラフィックを挿入
- ネット上の素材ではなく、一次情報となる独自の写真などを使用
②抽象的なアイキャッチを図解に変換
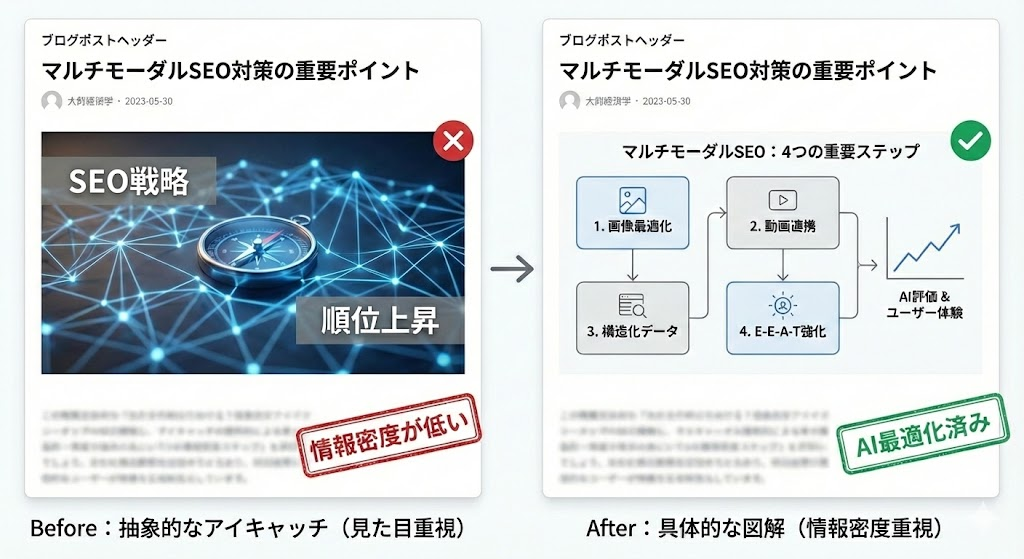
各H2見出しの直下に配置されるアイキャッチ画像も、マルチモーダルAIにとっては重要な解析対象です。
これまで、H2直下の画像はセクションの区切りや、単に「見栄え」を良くするための抽象的なイメージ画像が採用されるケースが多かったと思います。
しかし、AIにとって意味を持たない画像は、評価の機会損失になります。
- H2直下の抽象的なイメージ画像は、すべてそのセクションの内容を表す図解に変換
- ゼロからの図解制作が困難な場合は、画像生成AIツールなどを活用して効率化
③画像の高画質&軽量化
マルチモーダルAIは、画像をピクセル単位で内容を判別するため、不鮮明な画像は「解析不能」なデータとみなされるリスクがあります。
一方で、ページの表示速度(UX)も、SEOやAI認識において重要な評価軸であることに変わりはありません。
そのため、画像は高精細なディテールを維持しつつ、読み込みを阻害しない最適化が求められます。
- 被写体の輪郭やテキストが鮮明に見える、十分な解像度を持った画像素材を使用
- 「WebP」などの次世代フォーマットを活用し、画質を落とさずにファイルサイズを軽量化
④YouTube展開と記事との連携
マルチモーダルAI時代において、SEOの最大の競合はYouTubeです。
AIはテキストよりも動画内の実演や解説を「質の高い回答」と判断する傾向が強く、実際にYouTubeはAIに引用されやすいドメインであることが、データでも明らかになっています。
そこで、SEO記事とYouTube動画で情報を補完し合うことで、Youtube動画だけやSEO記事だけのコンテンツよりも、AIに認識性で有利に立ち回ることができます。
同時展開することは、なかなか簡単なことではありませんが、強力なマルチモーダルAI対策になります。
- 記事の要点を解説したYouTube動画を作成し、記事の適切な箇所に埋め込む
- 動画のチャプター設定と記事の見出し構成を同期させ、AIの解析を支援する
- 記事と動画の間で相互リンクを貼り、コンテンツの関連性を強化する
⑤alt属性の再定義

alt属性(代替テキスト)の役割は「検索エンジンへのキーワード通知」から、「AIが解析する情報の答え合わせ」へと再定義します。
AIは画像を見ることができますが、その「解釈」が作り手の意図と100%一致するとは限りません。
alt属性に画像内のロジックや詳細な事実を記述することで、AIの誤認を防ぎ、コンテンツの信頼性を担保する「補足データ」として機能します。
例えば、上のような画像の場合で考えます。
- alt=”手作りのお弁当”
- 記事のメインキーワードである「手作り 弁当」を使用したが、AIにはこの情報だけではどのような目的で誰に向けて作られた弁当かまでは分からない。
マルチモーダル対応
- alt=”栄養バランスと彩りを考えた男の子向けの手作り弁当の盛り付け例”
- 男の子向けで栄養を考えた母親が作るためのお弁当だと分かる。また配色を考えた上で盛り付けたという意図も理解できる。
このように、とりあえずキーワードを拾っておくという単純な考え方はやめて、画像のその先に隠れた目的や意図まで書き込むことで、AIが正しく認識しやすくなります。
ただし、従来のようにキーワードを不自然に詰め込んだり、あまりに長いテキストはGoogle評価を落とす可能性があるため、40文字前後を目安に設計するのが無難です。
⑥複数のモダリティ内での整合性を保つ
マルチモーダルAIは、記事の「テキスト」「画像」「動画」を、一つの共通空間で理解しようとします。
ここで最も注意すべきは、以下のような異なるモダリティ間での意見の食い違い(ズレ)です。
| テキスト | 「Aが一番おすすめ」 |
|---|---|
| 図解 | 「AもBも良い」 |
| 埋め込み動画 | 「AやBもいいが、Cも別に悪くはない」 |
一見、これらは「Aが良い」という事実は変わりません。
ただ、全体としてみたときに、結論がぼやけているため、AIにとってはそれが理解する時のノイズになります。
このような不整合があるコンテンツは、AIから「情報の正確性が低い」「専門性に欠ける」と見なされ、AI回答への採用率に悪影響を及ぼします。
ユーザーの利便性を損なうだけでなく、AIからの信頼を失う大きなリスクとなります。
画像や動画を作る余裕がない時のマルチモーダルAI対応策

すべての記事に対して、動画やインフォグラフィックを完備するのは、リソースの限られた現場では難しいです。
しかし、リッチな視覚情報が不足していても、他の手段でマルチモーダルな文脈で評価させることは十分に可能です。
ここでは、最小限の手間で「AIへの伝達力」を確保するための代替策を紹介します。
- 実体験の要素は写真で補完する
- 情報の構造化で画像・動画がなくても理解しやすくする
- AIO対策業者に依頼する
- ツールを使って簡単に図解化する
実体験の要素は写真で補完する
図解やインフォグラフィックを作るスキルがない場合でも、「自分で撮った写真」を1枚添えるだけで、コンテンツの価値は向上します。
写真は、著者がその場で撮影しなければ得ることができない「一次情報」としての価値が高い画像です。
凝った加工やデザインが施されていなくても、現場のリアルを伝える写真は、それ自体がAIが好むE-E-A-TのExperience(経験)を証明する強力なエビデンスになります。
以下は、写真を既存記事に落とし込む、具体的な例です。
-
インタビュー記事
取材中の自然な表情や、対話している雰囲気が伝わる顔写真があるだけで、AIに「実際に人に会って書かれた信頼性の高いもの」と認識させられる。 -
手順解説・ノウハウ記事
綺麗な図解を作る代わりに、実際に作業している「自分の手元」をスマホで撮る。そのリアルな工程がAIに「実体験に基づいている」という確信を与えられる。 -
レビュー記事
商品の全体像だけでなく、質感やサイズ感がわかる接写、あるいは実際に使っているシーンの写真を添え、「実際に購入した体験」を伝える。
情報の構造化で画像・動画がなくても理解しやすくする
視覚情報が不足している場合でも、論理構造やデータの形式を整えることで、AIへの伝達力を十分に補うことができます。
これは、図解が担うはずだった「情報の補足・要約」の役割を、別の手段で行うアプローチです。
主に以下の2つの手段があります。
-
箇条書きや表の活用
データの比較や手順の並びを整理することで、AIの情報理解をサポートできる。 -
構造化データ(JSON-LD)の実装
HowTo(手順)やFAQ(よくある質問)などの専用タグをコードに埋め込むことで、AIに情報を正しく認識させる。
AIO対策業者に依頼する
自社だけでAI検索に対応した記事制作が追いつかない場合、専門的なノウハウを持つAIO対策の業者に依頼することも有効な選択肢です。
AIO対策とは、ChatGPTやAI OverviewsなどのAI検索エンジンが、記事を回答の「引用元」として採用しやすくするために行う最適化対策のことです。
日々アップデートされるAIのアルゴリズムを的確に捉え、テキスト・画像・動画を横断した戦略的な最適化をワンストップで任せることができます。
AIO業者に依頼することで、次のようなメリットがあります。
- 目まぐるしく変わるAIのアルゴリズムやトレンドに対応できる
- 社内リソースや知識がなくてもAIO対策ができる
- 代行してもらうため、自社の事業に専念できる
ただしAIO業者と言っても、「AIO」という言葉自体、2025年あたりから本格化した新しい概念です。
そのため、AIO業者としての実績を持つ業者はほぼいません。
そこで、SEOの実績を見ることでAIO業者を見定めることをおすすめします。
なぜなら、SEO対策は、E-E-A-Tや、結論ファーストの文章、構造化データのマークアップのようなAIO対策と共通する点が多いからです。
SEO対策の延長で、AIO対策に取り組んでいる業者は、すでに一定の知見を持っている状態と言えます。
ツールを使って簡単に図解化する
「デザインセンスがないから図解は無理だ」と、諦める必要はありません。
現在は、テキストを入力するだけでAIが情報の要約から構成までを自動で行い、プロのような図解を生成できるAIツールが普及しています。
これからの時代、プロのデザインスキルを習得することに膨大な時間を割くのではなく、「AIツールに上手く描かせるためのディレクション」にリソースを割く方が、コストと効率の面で圧倒的に有利です。
また、AIツールを使いこなして図解を制作することは、ある意味マルチモーダルAIを活用していることそのものです。
マルチモーダルAI対策を推進する立場として、まず自分自身がこれらを使いこなし、一定の理解を深めておく必要があります。
そうでなければ、「AIが何を読み取り、どのような情報に価値を感じるのか」という本質的な判断ができず、実効性の高い指示を出すことができないからです。
マルチモーダルAI対策に使えるツール
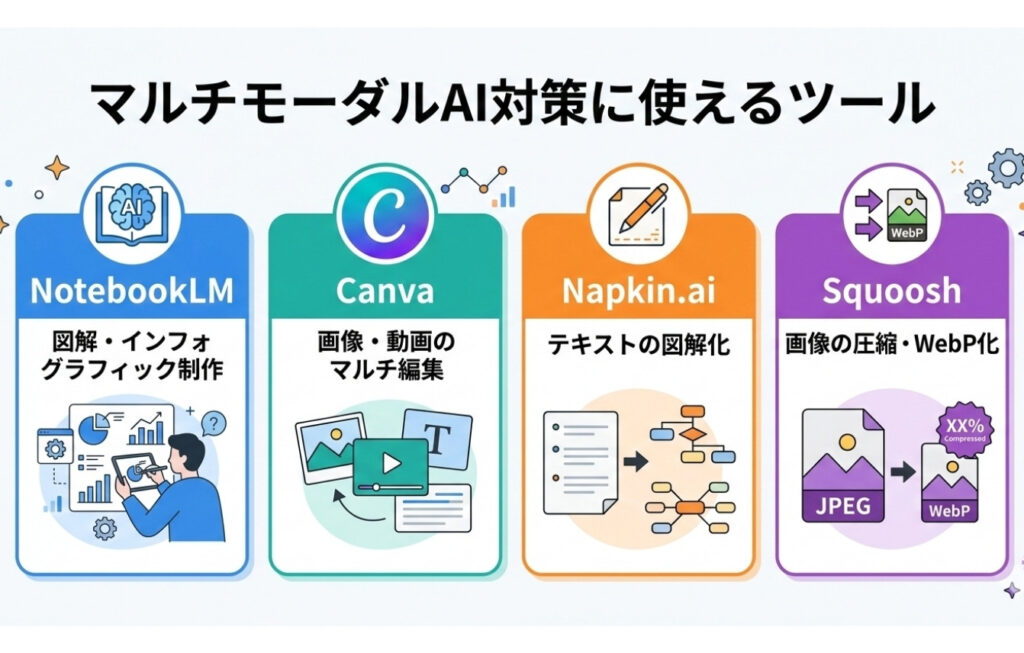
マルチモーダルAI対策を成功させるには、「情報の多角化」と「制作の効率化」の両立にあります。
テキストの内容を正しく反映した図解や、視覚情報を補完する動画をすべて手作業で用意するのは、リソースの限られた現場では現実的ではありません。
そこで重要になるのが、AIの力を借りて、AIに伝わりやすい素材を生成・最適化するツールの活用です。
執筆の現場で即戦力となる4つのツールを、実際のツール画面を交えて紹介します。
| NotebookLM | 図解・インフォグラフィック制作 |
|---|---|
| Canva | 画像・動画のマルチ編集 |
| Napkin.ai | テキストの図解化 |
| Squoosh | 画像の圧縮・WebP化 |
SEO業界20年、取引実績5,000社で多種多様な企業様の課題解決と成長をサポートしてまいりました。
完全内製の一貫体制でSEO支援を行い、専属のSEO研究チームが「分析→実装→検証→改善」 のサイクルを高速で回します。
問い合わせ増加・ブランディングを全力でサポートいたします。
NotebookLM(図解・インフォグラフィック制作)
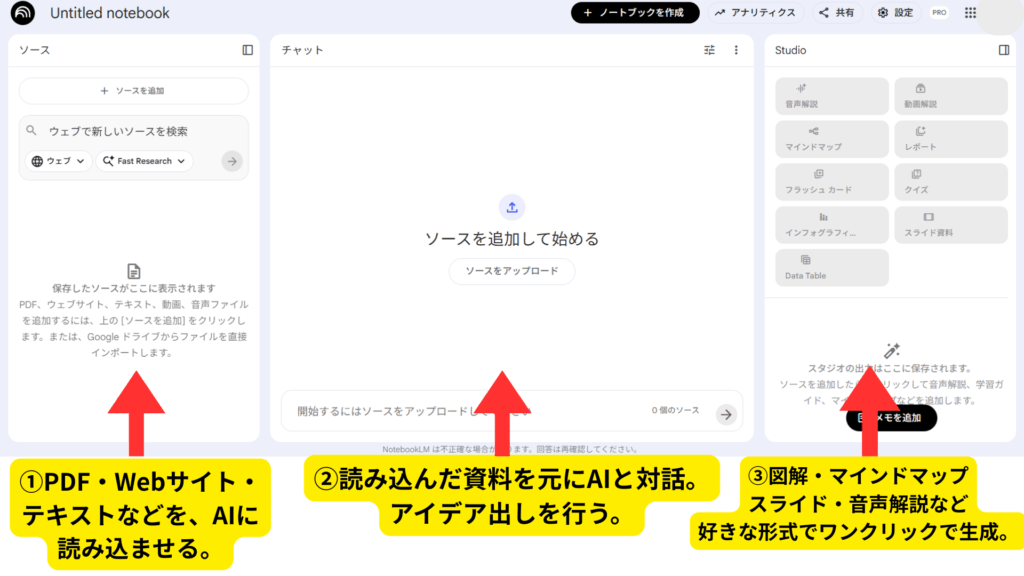
NotebookLMは、自分が選んだ資料(ソース)だけを情報源(ソース)として扱う、Google提供のAIツールです。
最大の特徴は、インターネット上の不確かな情報ではなく、「自分がアップロードした資料からのみ回答を生成する」という点にあります。
NotebookLMの使い方は、以下の3ステップです。
-
ソースの追加:
自分が執筆した原稿、一次資料(PDFやWebサイトなど)を読み込ませる。 -
チャットで構成案の作成:
「この内容を読者に伝えるための図解の案を出して」などと指示し、構成を練る。 -
Studio機能で出力:
マインドマップ、インフォグラフィック、音声解説、スライド資料などを選び、ワンクリックで生成する。
このツールの最大の利点は、選んだ資料のみをベースに生成するため、ハルシネーション(嘘)を防ぎ、著作権的にもクリーンな状態で独自性の高い図解を制作できる点にあります。
また、取り込んだ記事の本文と図解のロジックが一致するため、AIに対しても「情報の整合性が取れた、信頼性の高いコンテンツ」であることを証明できます。
Canva(画像・動画のマルチ編集)
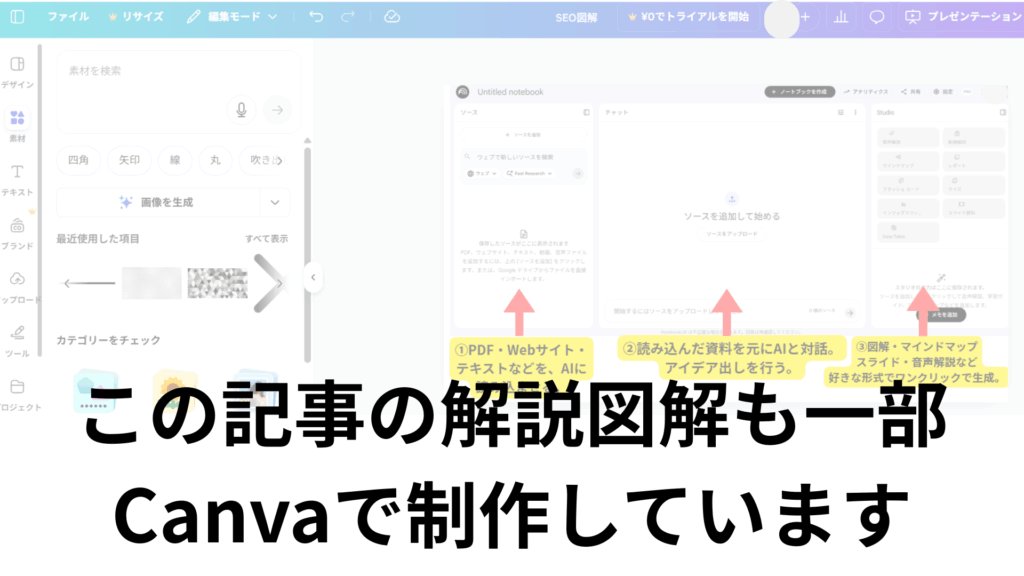
Canvaは、デザインの専門知識がなくても、ブラウザ上で直感的に高品質な画像や動画を制作できるオールインワンのクリエイティブツールです。
静止画の図解だけでなく、動画やSNS用の投稿まで一括で管理できるため、マルチモーダルなコンテンツ制作におけるハブとして機能します。
実は、この記事で使用している解説図解の一部も、Canvaを活用して制作しています。
執筆と並行して「ここを図解にしたい」と思った瞬間に、素材を組み合わせたりスクリーンショットに注釈を入れたりできる機動力は、記事制作において大きな武器になります。
- AIでどうしても思い通りにいかない図解をサッと手直しできる
- 保存しておけば、過去の図解の修正が簡単
- SNSのショートやYouTube用など、各プラットフォームに最適化した出力ができる
- そのまま使えるデザインテンプレートも多い
Napkin.ai(テキストの図解化)

Napkin.aiは、入力したテキストをAIが瞬時に解析し、論理構造に合わせた図解を自動生成してくれるツールです。
デザインの知識がなくても、文章を流し込むだけで「情報を視覚化」できるため、マルチモーダルAI対策における「意味のある図解」を量産するのに最適です。
上の図は、実際にこの記事の中の一つの文章から、複数のパターンで図解化した様子です。
このようにシンプルながらも、自分の好きな形式やカラーにして、オリジナリティを出せるところも大きなメリットです。
- 執筆した文章をコピペして、ボタンを押すだけで出力される。
- 同じ文章からでも「フローチャート」「ピラミッド型」「サイクル図」など多様なパターンを選べる。
- 出力後にカラーやテキストの微調整も可能。
Squoosh(画像の圧縮・WebP化)
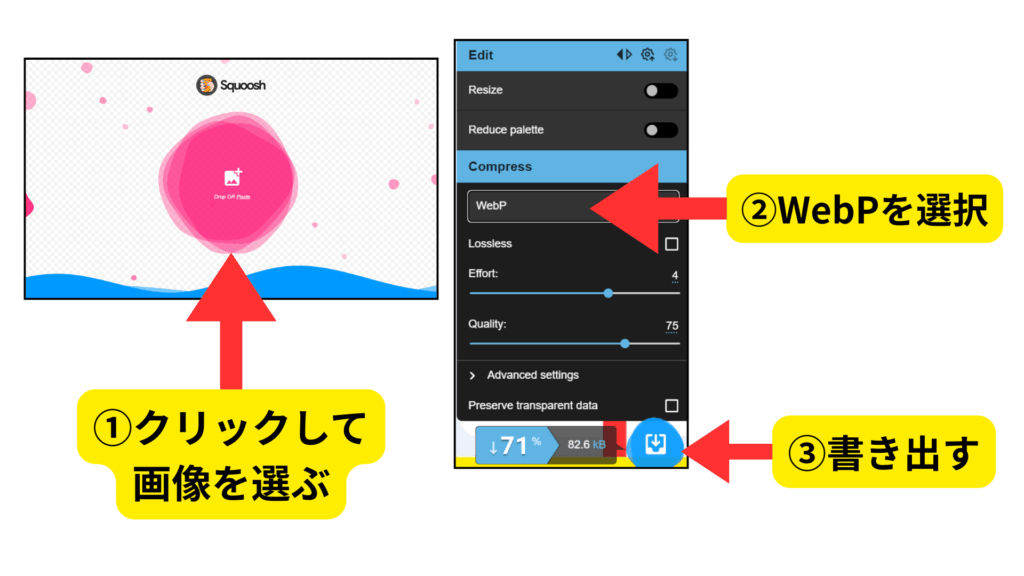
マルチモーダルなコンテンツにおいて、高品質な画像は不可欠ですが、ファイルサイズが重すぎるとサイトの表示速度を低下させ、AIによるクロール効率も悪くなります。
そこで重宝するのが、Googleが提供する無料の画像圧縮ツールSquooshです。
このSquooshを活用して、画像を「WebP」という形式へ変換・圧縮することで、表示速度を改善しAIに評価される画像にすることができます。
WebP(ウェッピー)とは、Googleが開発した次世代の画像フォーマットです。
従来のJPEGやPNGと比べて、画質を維持したままファイルサイズを劇的に軽量化できるのが特徴です。
Squooshを使えば、専用ソフトをダウンロードすることなく、ブラウザ上で誰でも無料でこのWebP化を行うことができます。
-
クリックして画像を選ぶ:
圧縮したい画像をドラッグ&ドロップするか、直接ファイルを選択。 -
WebPを選択:
右下の「Edit」パネルにあるフォーマット選択から「WebP」を選択。 -
書き出し:
右下のダウンロードボタンをクリックして保存。
マルチモーダルAIに関するよくある質問(FAQ)
マルチモーダルは、最新のAIモデルに搭載された機能のため、疑問を抱くことも多いと思います。
ここでは、マルチモーダルAI対策(AIO)を進める上で、多くのライターやディレクターが抱く疑問をまとめました。
Q:動画編集のスキルがないとSEOでは勝てませんか?
必ずしも高度な編集スキルは必要ありません。
大切なのは「動画のクオリティ」そのものではなく、テキストでは伝えきれない情報を「補完」できているかという点です。
スマホで撮影した手元の操作動画や、Canvaでスライドを繋ぎ合わせただけの簡易的な動画でも、それがユーザーの理解を助けるものであれば、AIからは「価値ある一次情報」と評価されます。
まずは凝った編集よりも、情報の正確さと分かりやすさを優先しましょう。
また、動画がどうしても難しければ、画像だけでもテキストのみの記事よりは、AIからの評価を高めることができます。
Q:過去のテキスト中心の記事はすべてリライトが必要ですか?
全記事を一気に修正する必要はありませんが、重要記事から順次リライトを推奨します。
まずは、検索上位を狙いたい記事や、現在トラフィックがある主要な記事から優先的に対応します。
すべての構成を変えなくても、既存のテキストに合わせて「オリジナルの写真を追加する」「AIツールで図解を1枚差し込む」といった部分的なリライトだけでも、AIの理解を促すことが可能です。
Q:生成AIで作成した画像を使っても問題ない?
SEOやGoogleの評価といった文脈から、生成AI画像の取り扱いが気になっている方も多いかもしれません。
結論から言えば、Googleの公式見解として、ガイドラインに沿った適切な使用であれば検索評価において全く問題ありません。
以下のようにGoogleの公式見解があります。
AI や自動化は、適切に使用している限りは Google のガイドラインの違反になりません。検索ランキングの操作を主な目的としてコンテンツ生成に使用すると、スパムに関するポリシーへの違反とみなされます。
参照:Google Search Central「AI 生成コンテンツに関する Google 検索のガイダンス」
このように、AI画像の使用そのものがペナルティになることはありません。
ただし、「ポリシー」と「著作権」の2点に注意を払う必要があります。
| ポリシーへの配慮 | 単なる順位操作を目的とした内容と無関係な画像の量産は危険。 |
|---|---|
| 著作権への配慮 | 他者の権利を侵害していないか細心の注意が必要。 |
本記事で紹介したNotebookLMのように、自身の一次情報をベースに図解化する手法を選べば、このリスクを最小限に抑えつつ、独自性と信頼性の高いコンテンツに仕上げることが可能です。
まとめ:マルチモーダルAIによって記事は「読む」から「見る」ものに
マルチモーダルAIの普及は、コンテンツ制作の本質を「読ませる」ことから「直感的に理解させる(見せる)」ことへとシフトさせました。
かつてのSEOでは、テキストを機械的に読み込ませる作業が本質でした。
現在は、AIが人間と同じように視覚や聴覚を持ったことで、コンテンツを画像や動画などに多角的に展開して、総合的な文脈で理解させる必要があります。
最後に、これからのマルチモーダルAI(AIO)対応で重要なポイントを振り返ります。
- テキスト以外の証拠(写真、図解、動画)を盛る
- 複数の証拠は結論を統一させる
- 自身もマルチモーダルAIを最大限活用する
マルチモーダルAIに対応していくことは、AIに理解を促すだけでなく、ユーザーの満足度を上げることにもつながります。
まずは一つ、マルチモーダルなAIツールを使って、図解を作成するところから始めてみてください。
自分から能動的にAIに参入していく姿勢こそが、これからのSEOで最も重要なことかもしれません。
